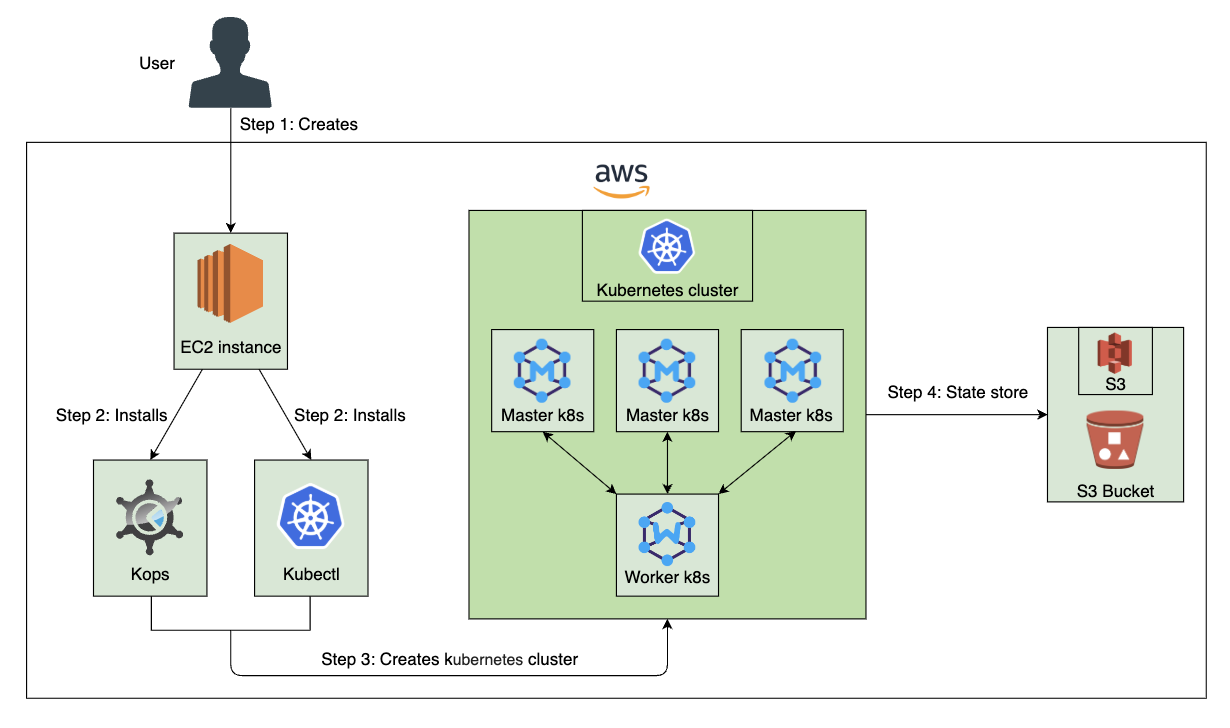
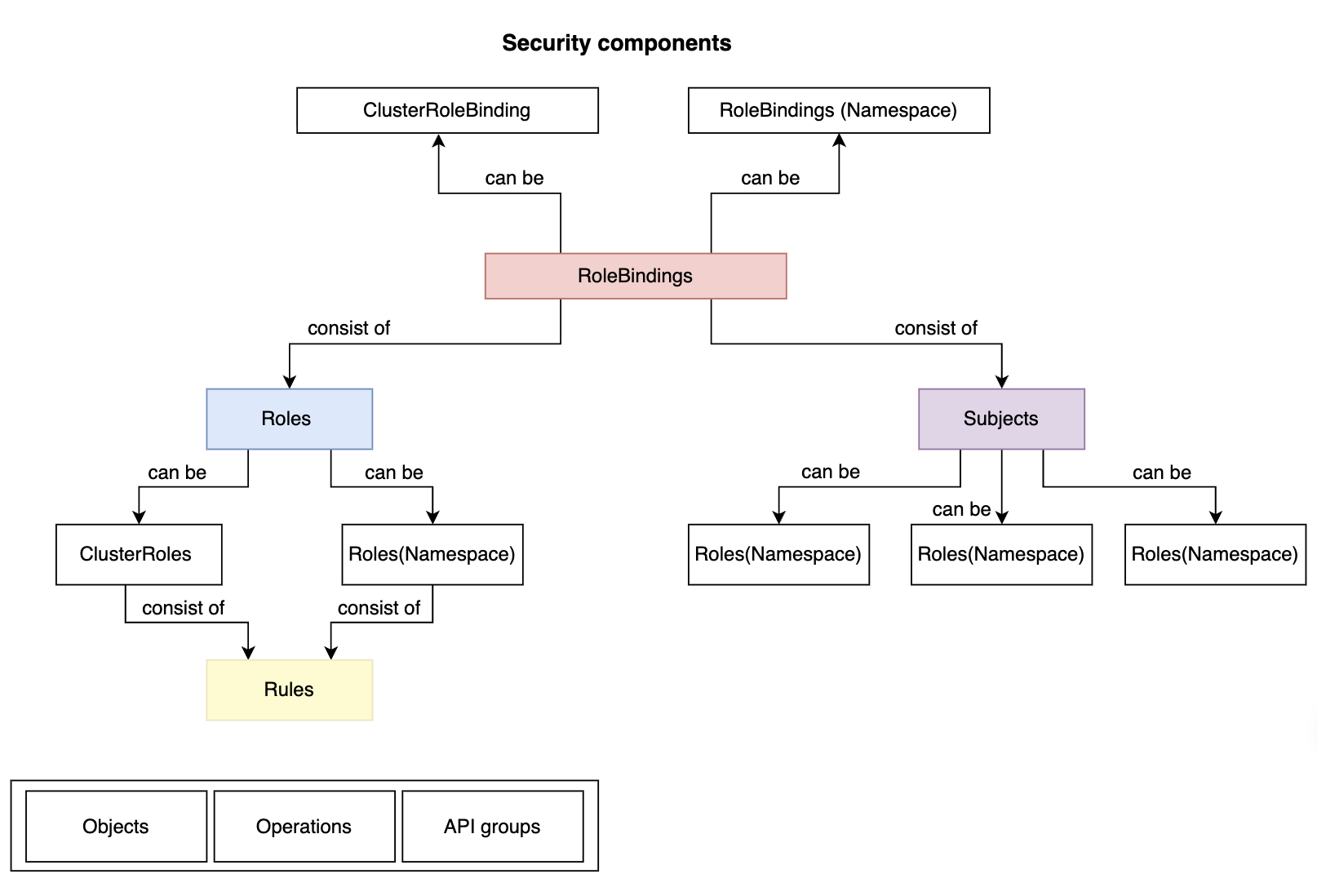
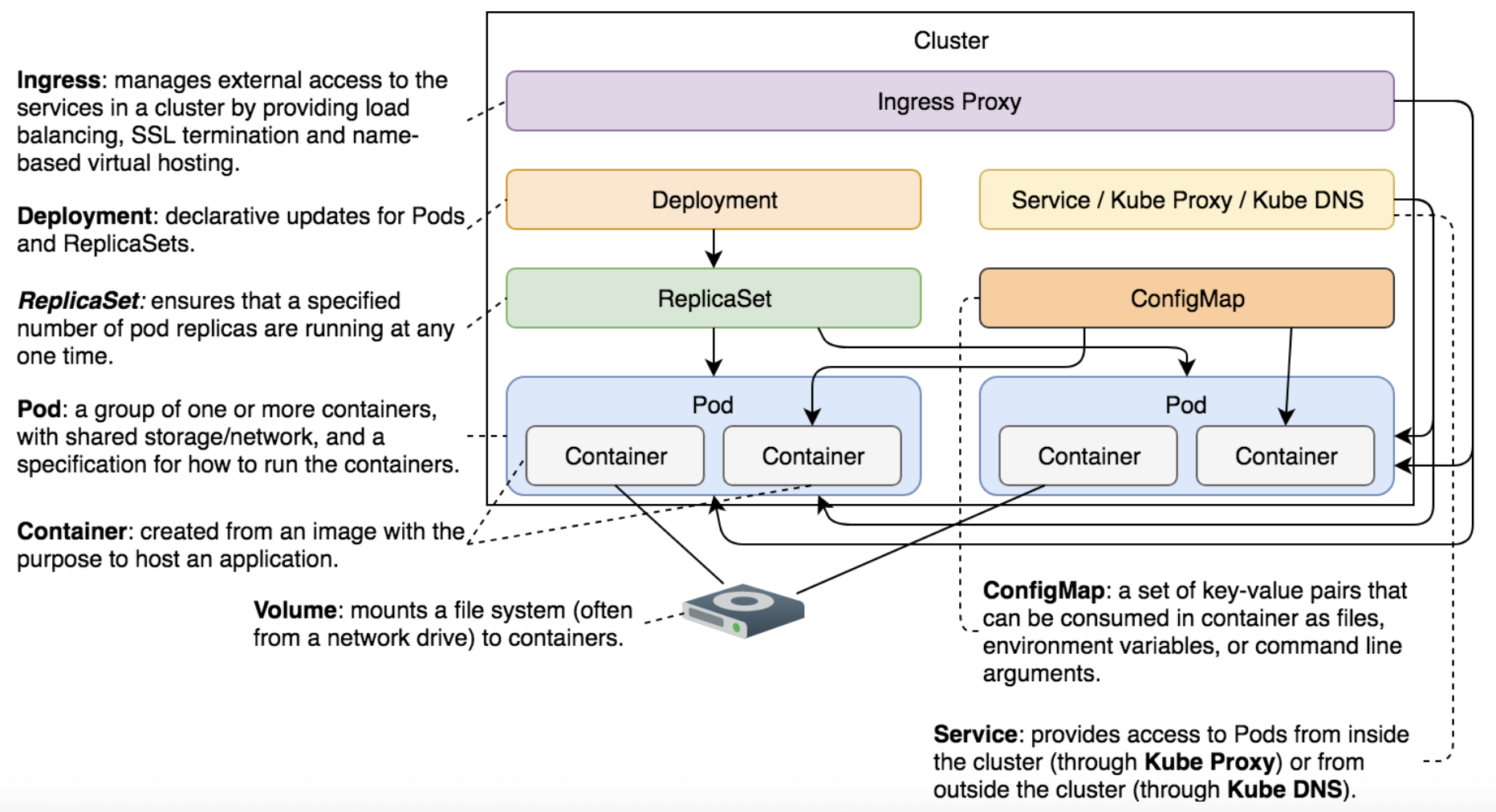
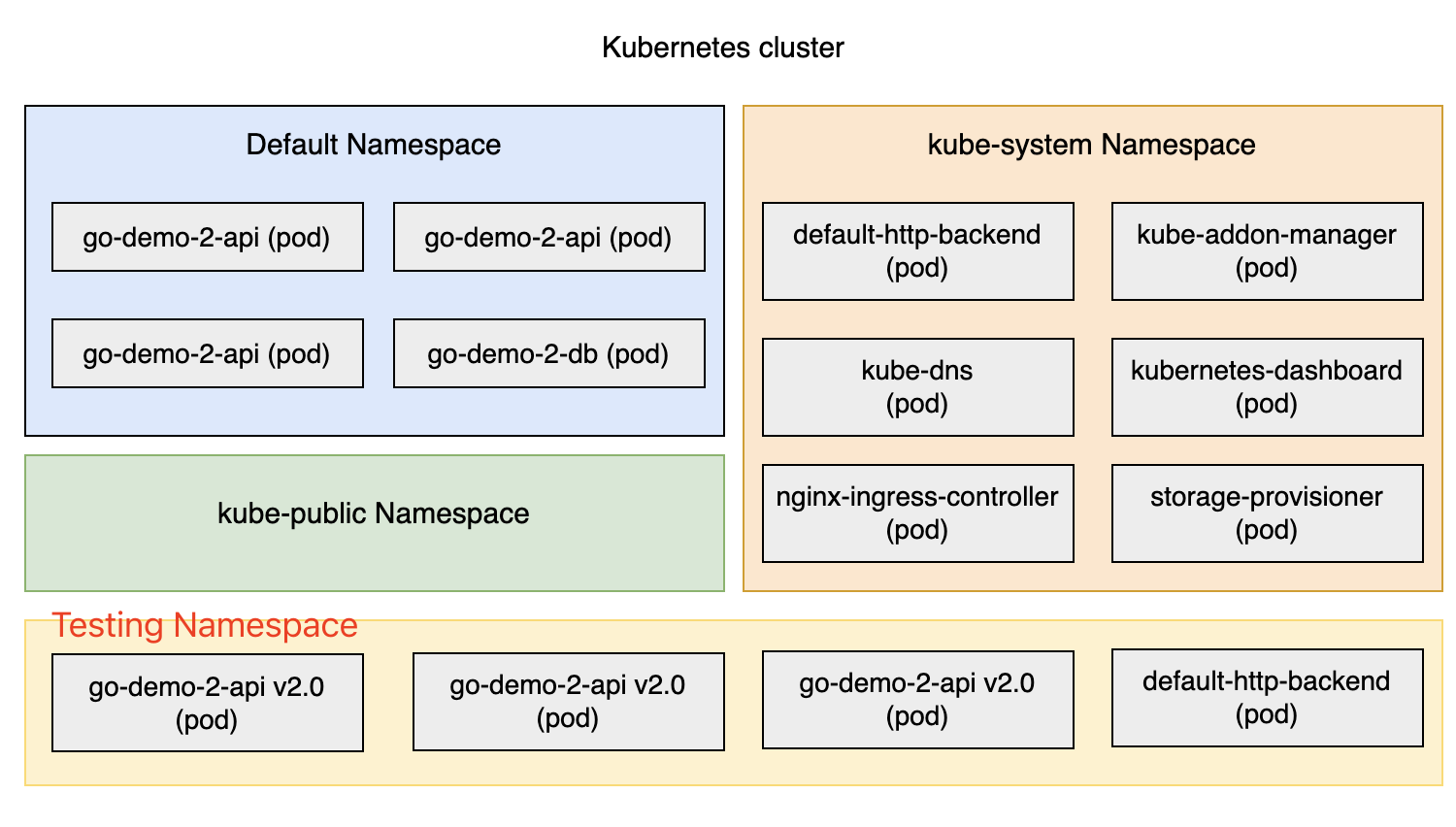
数据科学
· 3 min read
- Jupyter Notebook- 一种开源网络应用程序,用于创建和共享包含实时代码、可视化和文本的文档。
- Colab Notebook- 由谷歌托管的 Jupyter 笔记本,可免费使用 GPU 和机器学习工具。
- GitHub- Git 仓库托管服务,用于存储和管理代码以及跟踪更改。支持协作。
- 虚拟环境- 一种隔离的 Python 环境,允许安装用于特定应用程序的软件包,而不是全局安装。
- README 文件- 介绍和解释项目的文本文件。它包含的信息有助于他人理解和贡献。
- 需求文件- 列出运行应用程序所需的所有 Python 软件包依赖关系的文本文件。允许重复构建。
- Makefile- 包含一系列指令的文件,用于自动构建、测试和管理项目。
- 持续集成- 经常合并代码更改并自动构建和测试代码以快速发现问题的做法。
数据科学家的一天
数据推理分析框架
Data Science Structure
- Ingest
- EDA (Exploratory Data Analysis)
- Modeling: Learning Data -> Predict
- Conclusion: Strong Recommendation + Data support