使用管道进行数据运维
· 3 min read
关键术语
- AWS Step Functions- 一种无服务器协调服务,可让您使用可视化工作流协调分布式应用程序和微服务的组件。
- AWS Batch- 一种托管计算服务,可在 AWS 上调度和运行任何规模的批量计算工作负载。自动提供资源。
- AWS Glue- 无服务器 ETL 和数据集成服务,可为分析和机器学习准备和转换数据。
- ETL 管道- 从数据源提取数据、处理/清理数据并将其加载到目标数据库或数据仓库的提取、转换和加载管道。
- 无服务器管道 - 使用 Lambda、Glue、Batch 和 Step Functions 等云服务来构建可自动管理基础设施的数据管道。
- DataOps- 协作数据管理实践,侧重于通过自动化基础设施提高数据交付的质量和速度。
Step Functions
准备创建两个 lambda functions
创建 Step Function
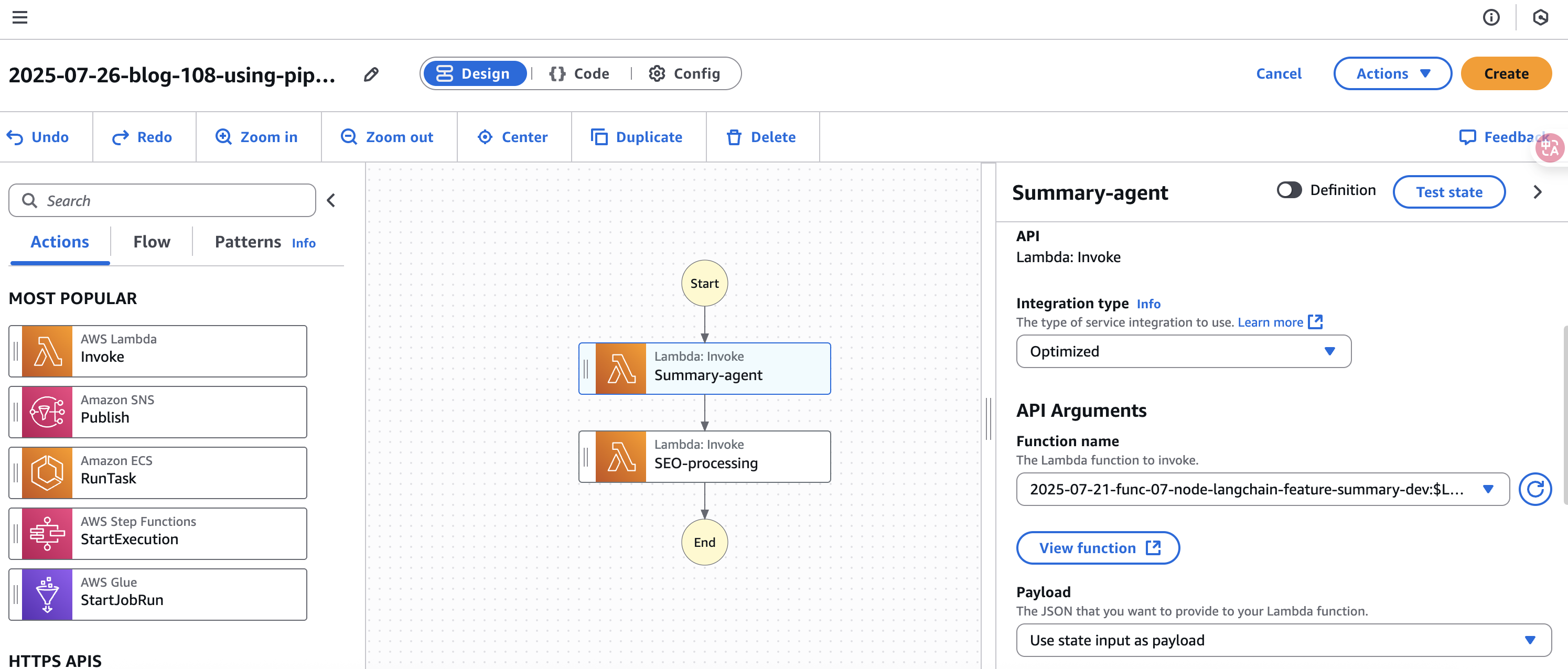
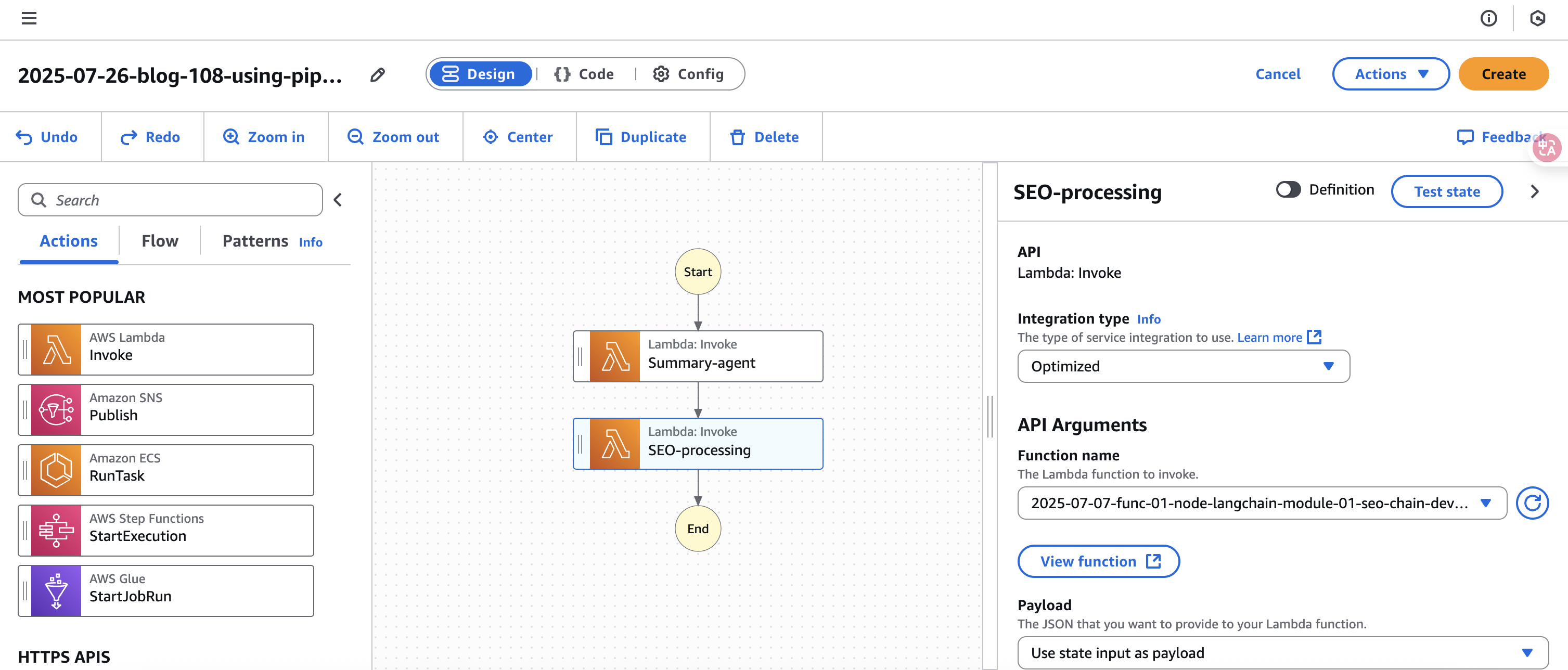
Step Function Definition
{
"Comment": "A description of my state machine",
"StartAt": "Summary-agent",
"States": {
"Summary-agent": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Output": "{% $states.result.Payload %}",
"Arguments": {
"FunctionName": "arn:aws:lambda:us-east-1:xxxxxx:function:2025-07-26-test-1-fruit:$LATEST",
"Payload": "{% $states.input %}"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2,
"JitterStrategy": "FULL"
}
],
"Next": "SEO-processing"
},
"SEO-processing": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Output": "{% $states.result.Payload %}",
"Arguments": {
"FunctionName": "arn:aws:lambda:us-east-1:xxxxxx:function:2025-07-26-test-2-chef:$LATEST",
"Payload": "{% $states.input %}"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 2,
"JitterStrategy": "FULL"
}
],
"End": true
}
},
"QueryLanguage": "JSONata"
}
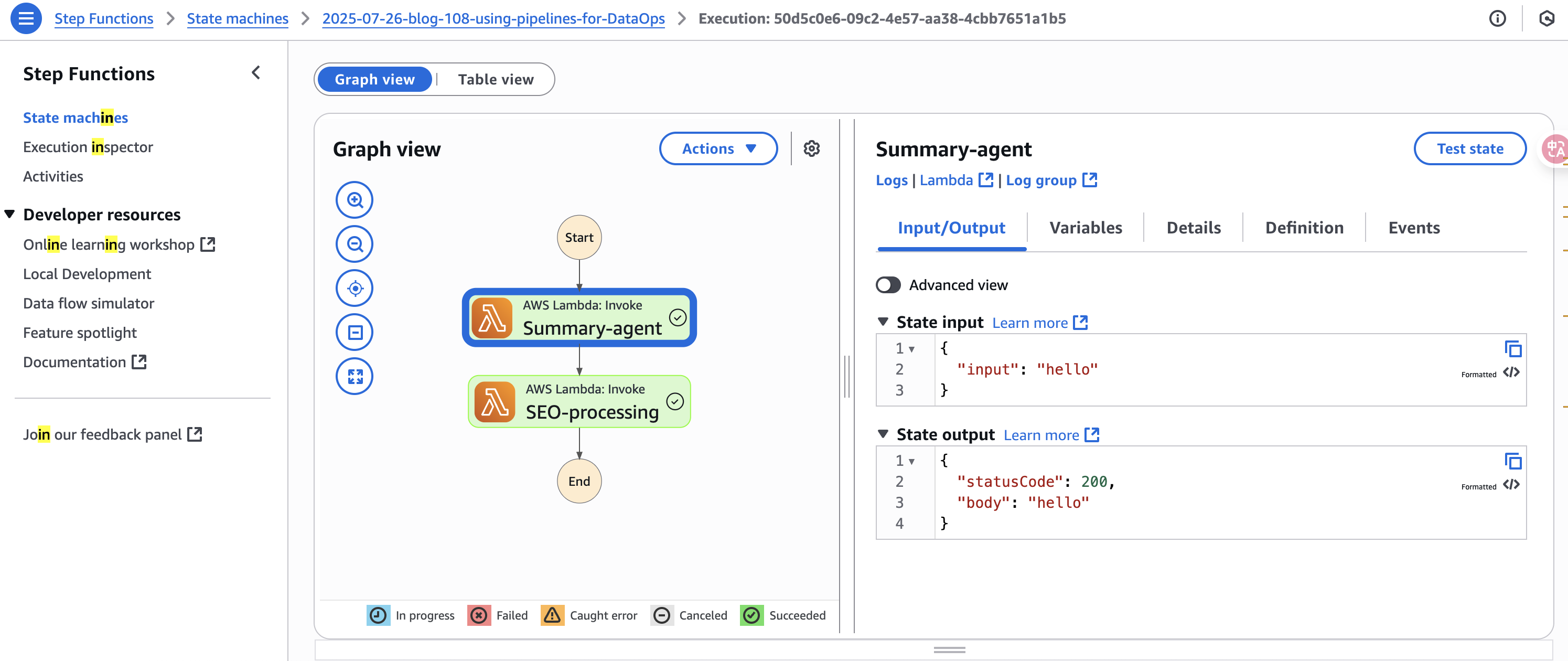
执行任务

Databricks 管道
- 准备好 Databrick Dataset, Azure Databricks Cluster (for connection)
- 将相关的 DATABRICKS Secrets 存到 Github Repository Secrets 在里面,这些 Secrets 将 inject into GitHub Codespaces 里面
- 使用 Python 语言+Databrick, Databrick-cli SDK,与 Cluster 通信,从而获得 Databrick 的数据
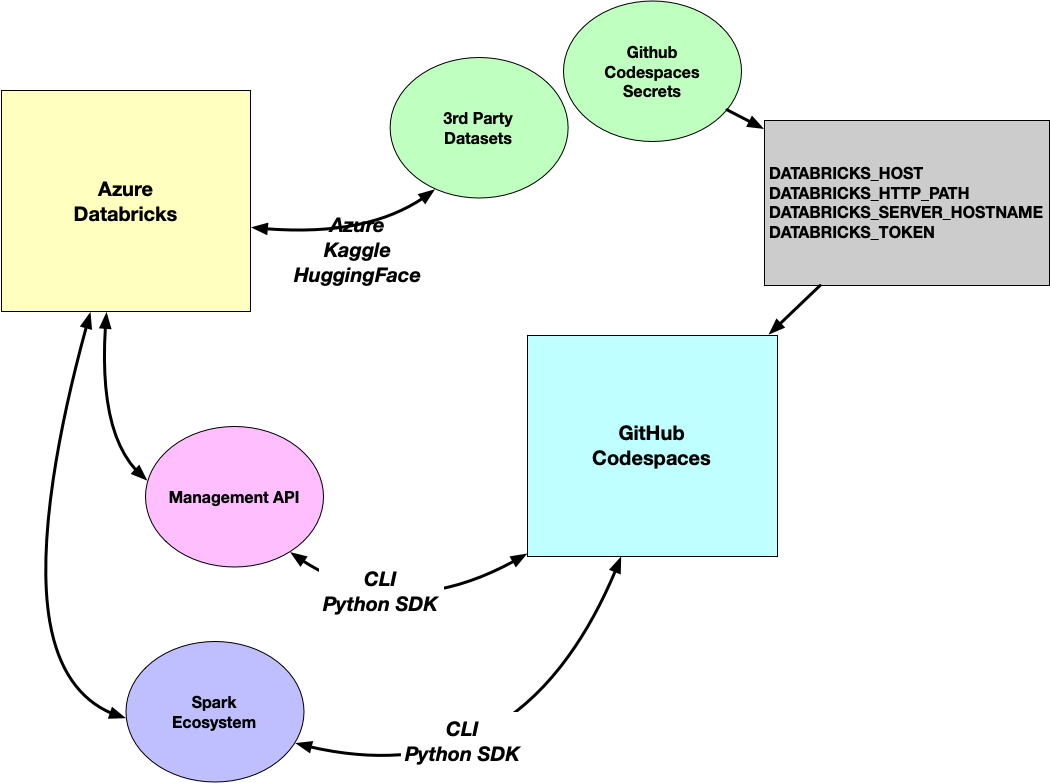
在 AWS 上构建数据输入管道

在 AWS 上转换传输中的数据
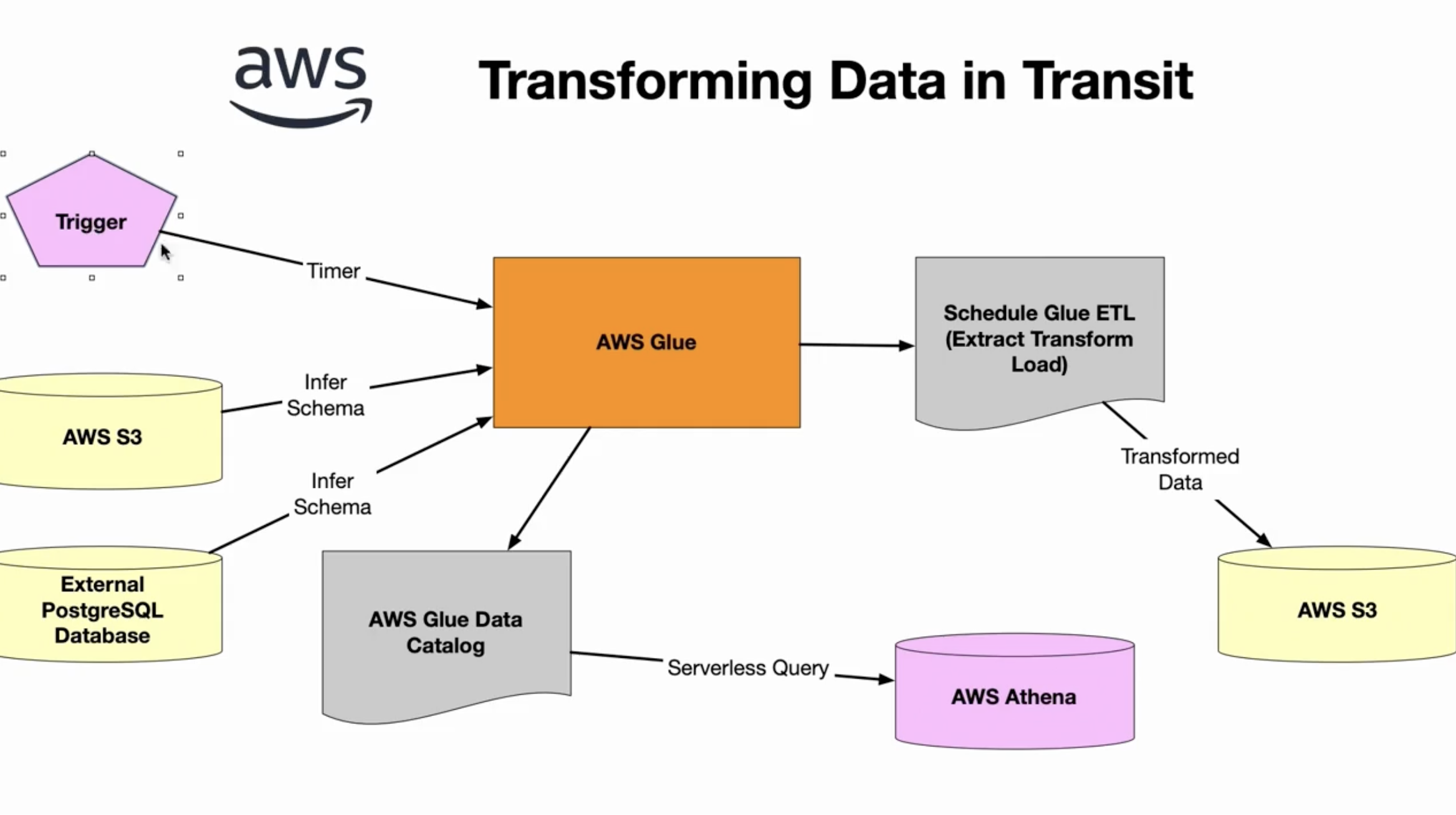
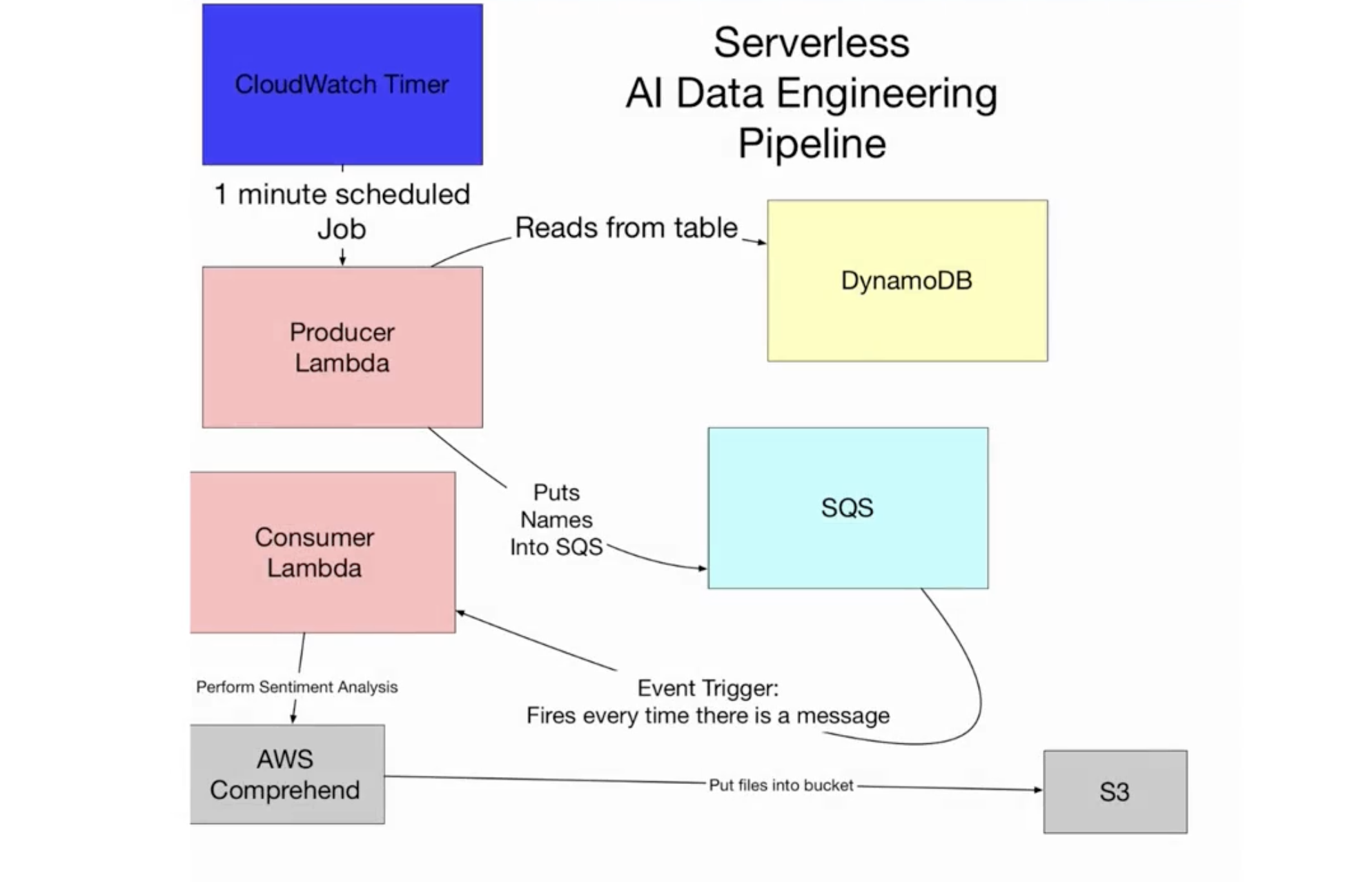
AWS 上的无服务器数据工程管道