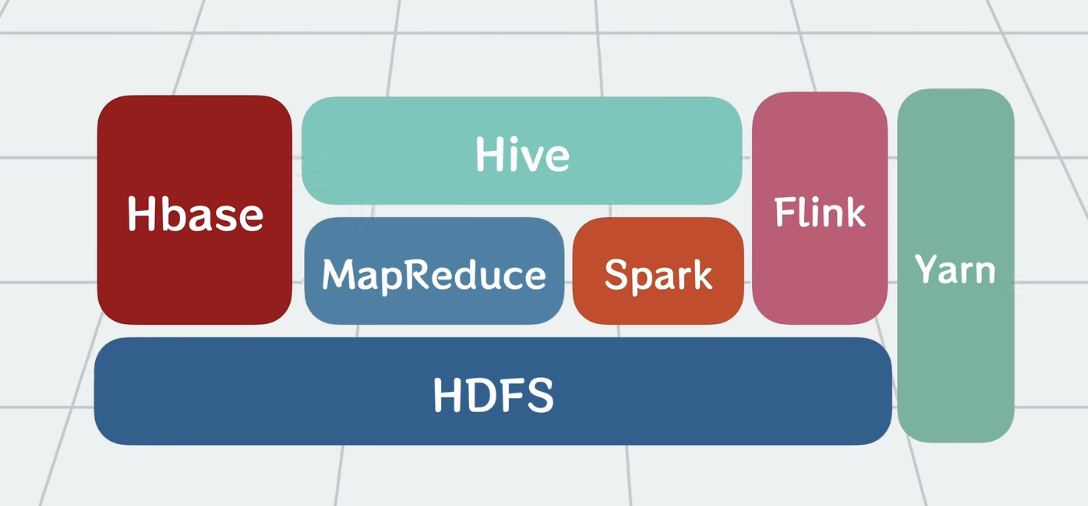
Hadoop 架构
· One min read
Linux 运维涉及广泛的系统管理、网络配置、安全维护和自动化工具等知识。以下是 Linux 运维的核心知识点分类整理,适用于日常工作、故障排查和性能优化:
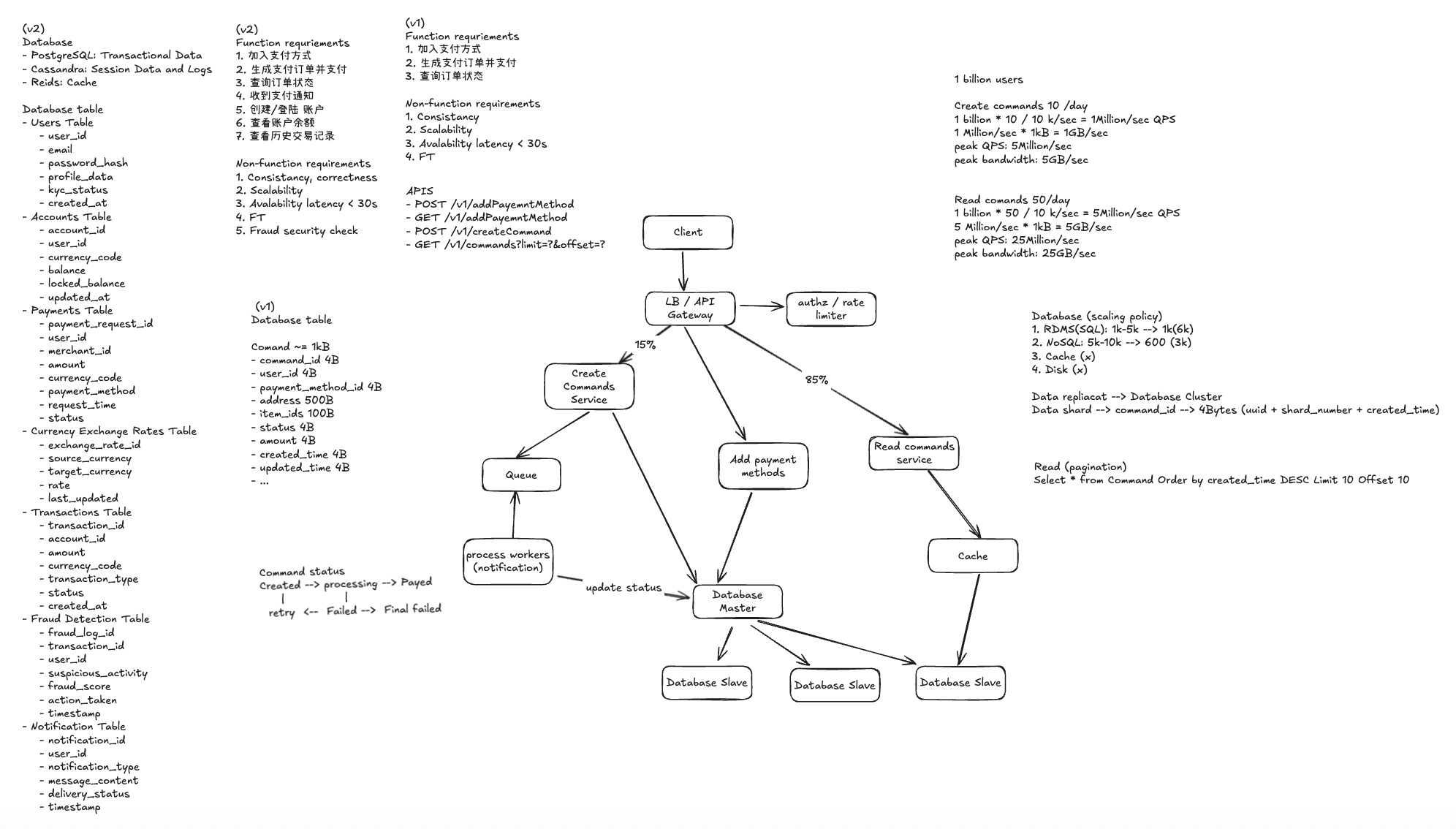
为了解决支付系统中高并发、容错、事务一致性等复杂问题,我们可以尝试应用以下设计模式和关键概念:
消息模型是消息中间件中用于定义消息传递方式的抽象模式,常见的除了**订阅/发布模式(Pub/Sub)和点对点模式(P2P)**外,还有其他衍生或组合模型。
| 模式 | 消息传递 | 耦合度 | 可靠性 | 扩展性 | 典型实现 | 典型应用 |
|---|---|---|---|---|---|---|
| 点对点, P2P | 一对一 | 低 | 高 | 中 | ActiveMQ, RabbitMQ | 异步任务、队列缓冲 |
| 发布/订阅 | 一对多 | 低 | 中 | 高 | Kafka, RabbitMQ | 事件通知、广播 |
| 请求/回复 | 双向 | 中 | 高 | 中 | RabbitMQ, ZeroMQ | RPC 调用 |
| 推/拉 | 可配置 | 低 | 可配置 | 高 | Kafka, RocketMQ | Fan-out |
| 流处理 | 连续 | 低 | 中到高 | 高 | Kafka Streams, Apache Flink | 日志处理、实时监控 |
序列化(Serialization)和反序列化(Deserialization)是数据处理中的两个核心概念,特别是在分布式系统和网络通信中尤为重要。
在系统设计中,了解硬件资源限制、数据库性能指标和常见数据规模是至关重要的。以下是整理的关键参数和参考范围,涵盖数据规模、硬件配置、数据库性能等方面:
| 字符类型 | 编码方式 | 存储大小 | 备注 |
|---|---|---|---|
| 英文字符 | ASCII 编码 | 1 个字符 = 1 byte | 适用于拉丁字母、数字和基本符号 |
| UTF-8 编码 | 1 个字符 = 1 byte | 兼容 ASCII,英文仍为单字节 | |
| 中文字符 | UTF-8 编码 | 1 个字符 = 3 bytes | 常用汉字占 3 字节,极少数生僻字可能占 4 字节 |
| GBK/GB2312 编码 | 1 个字符 = 2 bytes | 仅支持简体中文,非 Unicode 标准 | |
| 示例计算 | VARCHAR(100) UTF-8 | ||
| 英文 100 字 | 100 * 1B + 长度标识 ≈ 101B | ||
| 中文 100 字 | 100 * 3B + 长度标识 ≈ 303B |
说明:
VARCHAR(100) 字段在存储不同字符时的近似大小(包含长度标识)。| 数据类型 | 存储空间 | 示例 |
|---|---|---|
| CHAR(n) | 固定长度,不足补空格。英/中文均按定义的长度分配空间。 | CHAR(10) 英文=10B,中文=10B(实际存储内容可能更少,但空间固定) |
| VARCHAR(n) | 可变长度,按实际字符数+长度标识(通常 1-2 字节开销)。 | VARCHAR(10) 英文"Hi"=2B+1B,中文"你好"=6B+1B |
| TEXT | 可变长度,适合大文本(额外开销存储长度)。 | 英文长文本按实际字符数+开销 |
| INT | 通常 4 bytes(固定) | INT = 4B |
| BIGINT | 8 bytes | BIGINT = 8B |
| DATE/DATETIME | DATE=3B --> 4B, DATETIME=8B | DATETIME = 8B |
| 数据类型 | 数据大小范围 | 备注 |
|---|---|---|
| 单条用户数据(JSON 记录) | 1 KB - 10 KB | |
| 高清图片 | 1 MB - 5 MB | |
| 短视频(1 分钟) | 10 MB - 100 MB | |
| 长视频(1080p,1 小时) | 1 GB - 3 GB | |
| 数据库单表容量限制 | ||
| - MySQL/PostgreSQL | 单表建议 ≤ 500GB | 性能下降临界点 |
| - 分布式数据库(如 Cassandra) | 单表可支持 PB 级 |