类神经网络训练不起来怎么办?
· 3 min read
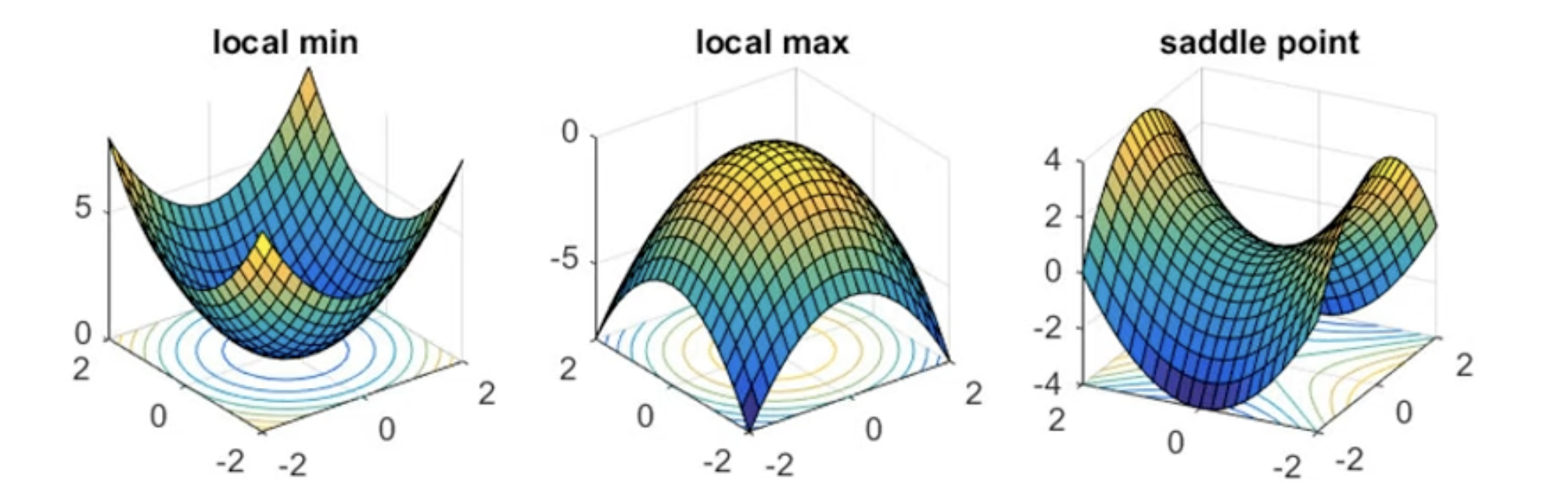
Critical Points
- Local minima
- Local maxima
- Saddle point (马鞍)
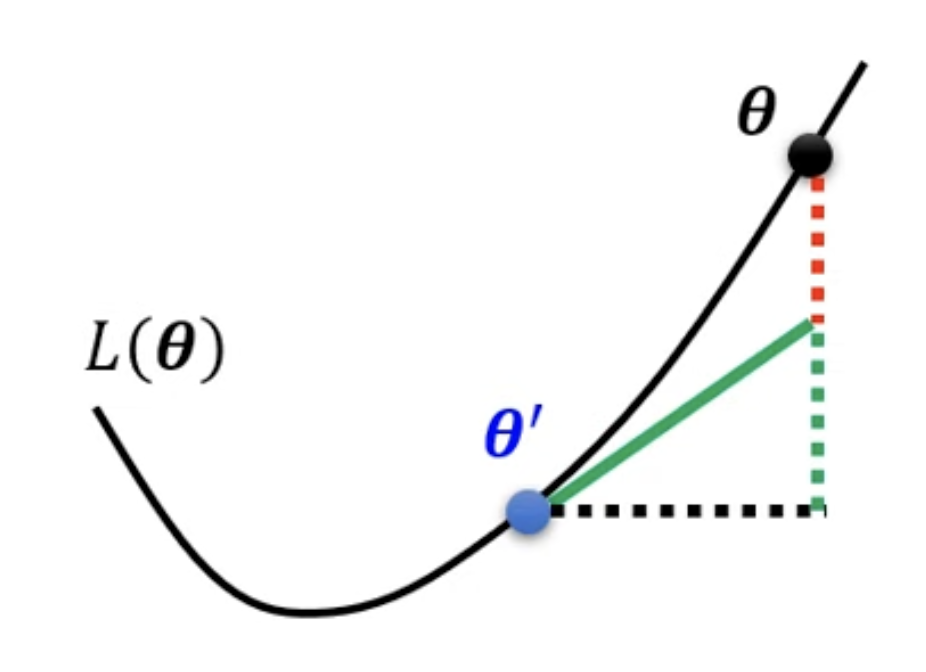
Tayler Series Approximation
The loss function around can be approximated as:
Gradient ( g ) is a vector:
Hessian ( H ) is a matrix:
No local minima
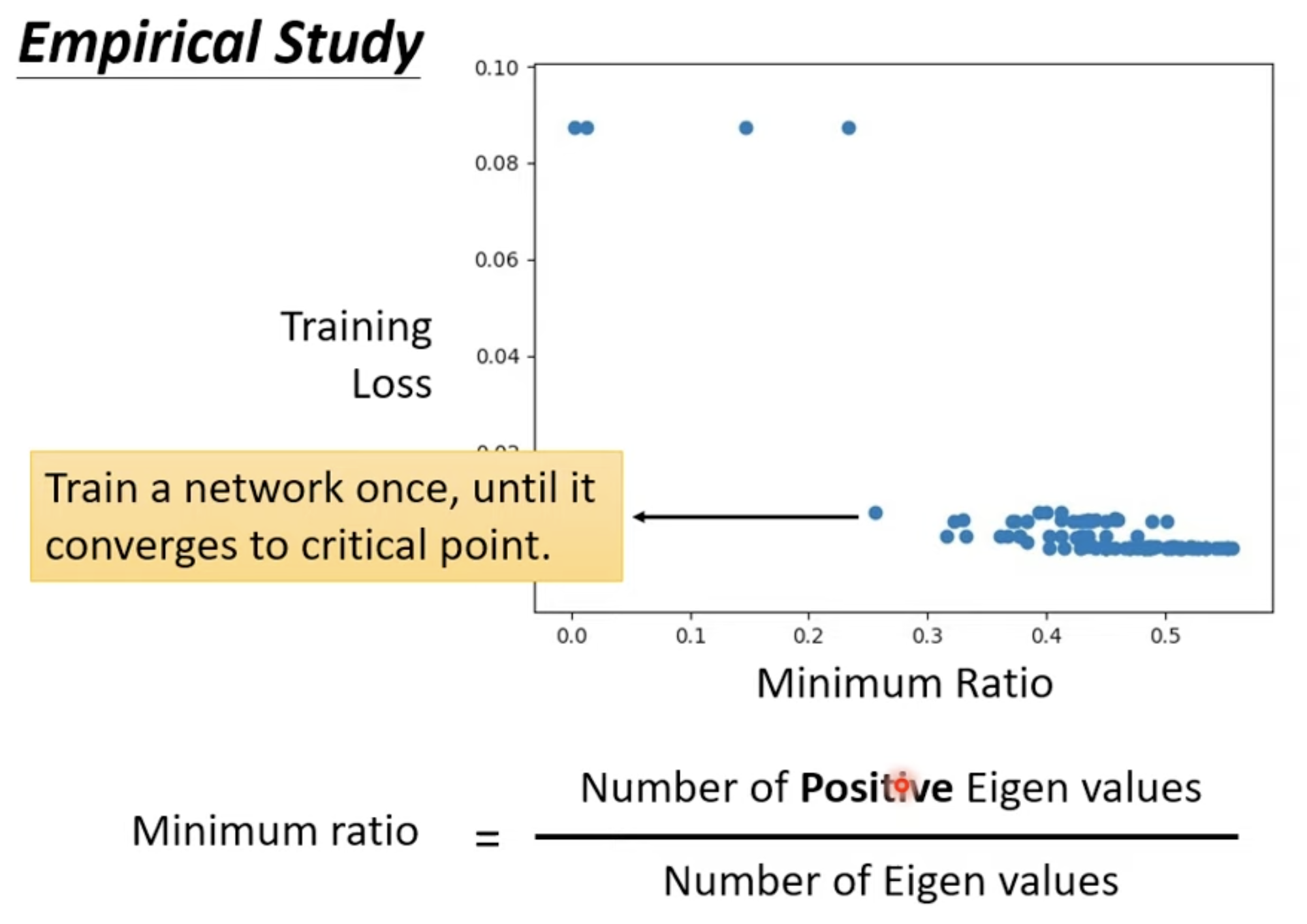
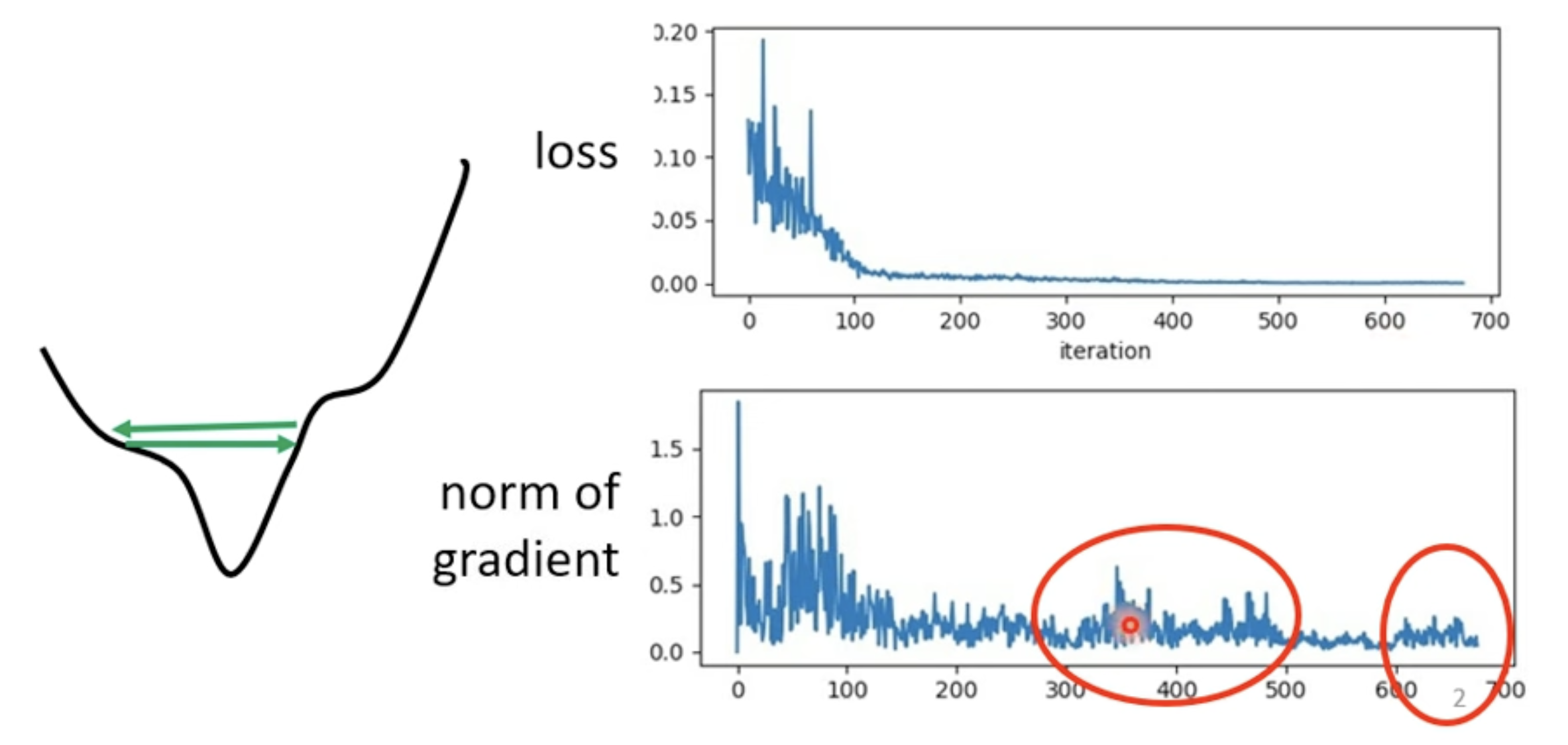
根据研究,我们其实很难找到 local minima, 因为 minimum ration 和图上的研究,我们获得最好的 Loss 的时候, Minimum Ration 大概就在 0.6 左右,这意味着我们其实还可以继续往 loss 更低的方向继续走;但是为什么训练可以停下来了呢,一个是成本问题,继续往下训练带来的成本增加和获得效果不成正比,二是你可能卡在了一个 saddle point.
Training stuck != Small Gradient

- [[blog/2025-06-30-blog-082-machine-learning-training-guide/index#训练技术#Adaptive Learning Rate 技术]]
With Root Mean Square

Optimizers
Adam: RMSProp + Momentum
- [[blog/2025-06-30-blog-082-machine-learning-training-guide/index#训练技术#Adaptive Learning Rate 技术#RMSProp]]
- [[blog/2025-06-30-blog-082-machine-learning-training-guide/index#训练技术#Momentum 技术]]
Summary of optimization

- 算不同的 momentum
- 算不同的
- 算不通的
训练技术
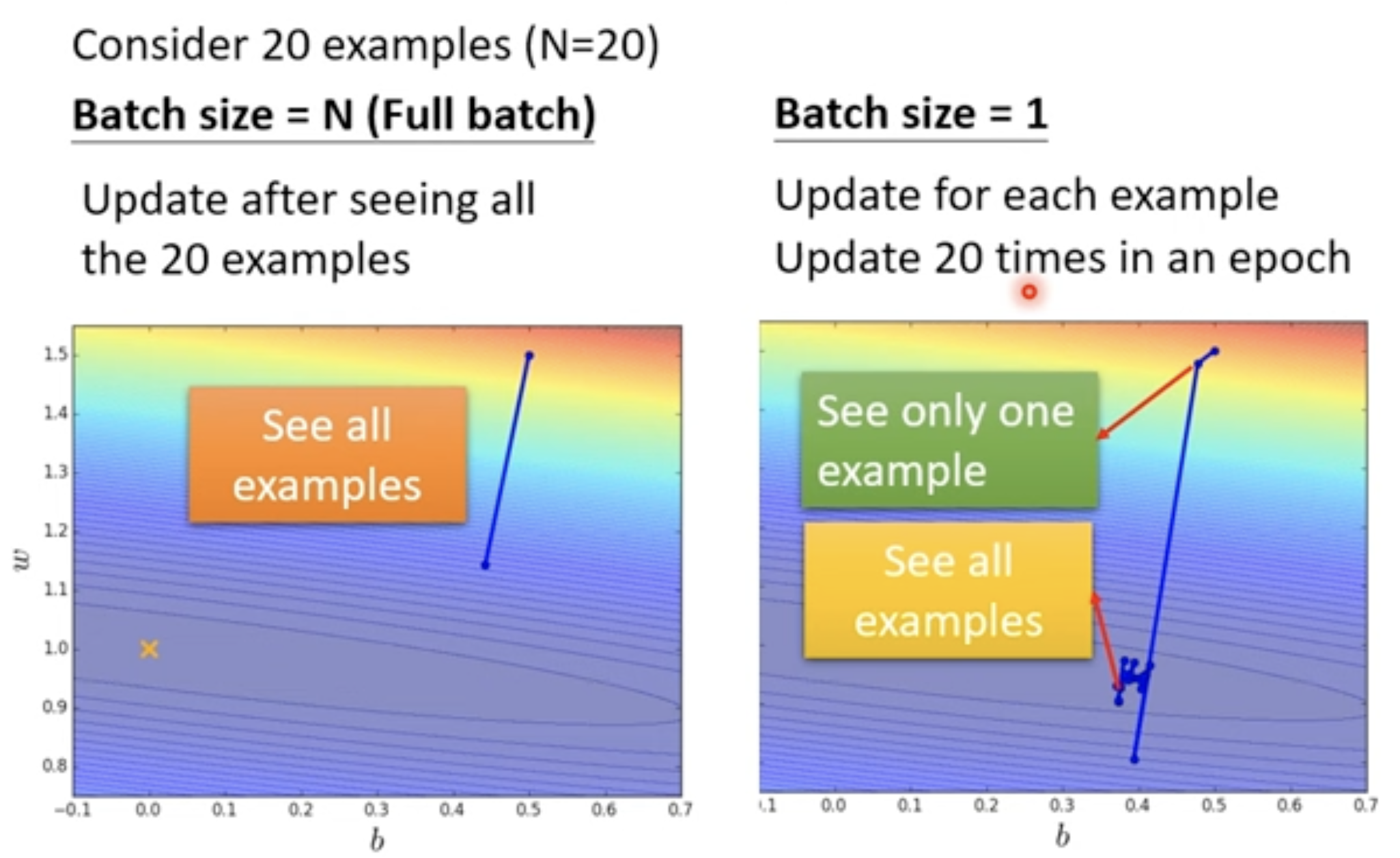
Batch 技术: Small Batch vs. Large Batch
| Metric | Small Batch | Large Batch |
|---|---|---|
| Speed for one update (no parallel) | Faster | Slower |
| Speed for one update (with parallel) | Same | Same (not too large) |
| Time for one epoch | Slower | Faster ✅ |
| Gradient | Noisy | Stable |
| Optimization | Better ✅ | Worse |
| Generalization | Better ✅ | Worse |
Momentum 技术
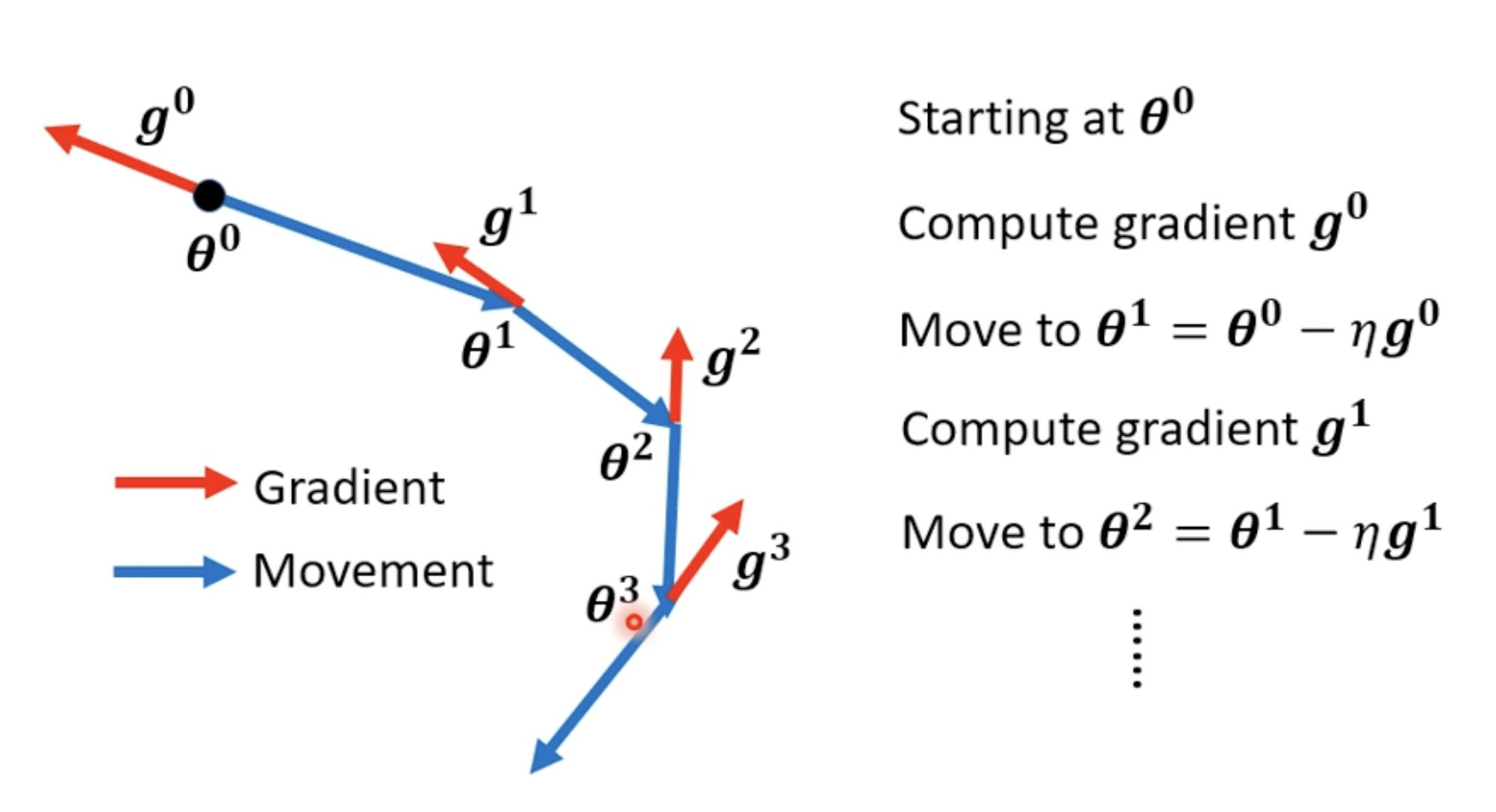
(Vanilla) Gradient Descent
Gradient Descent + Momentum
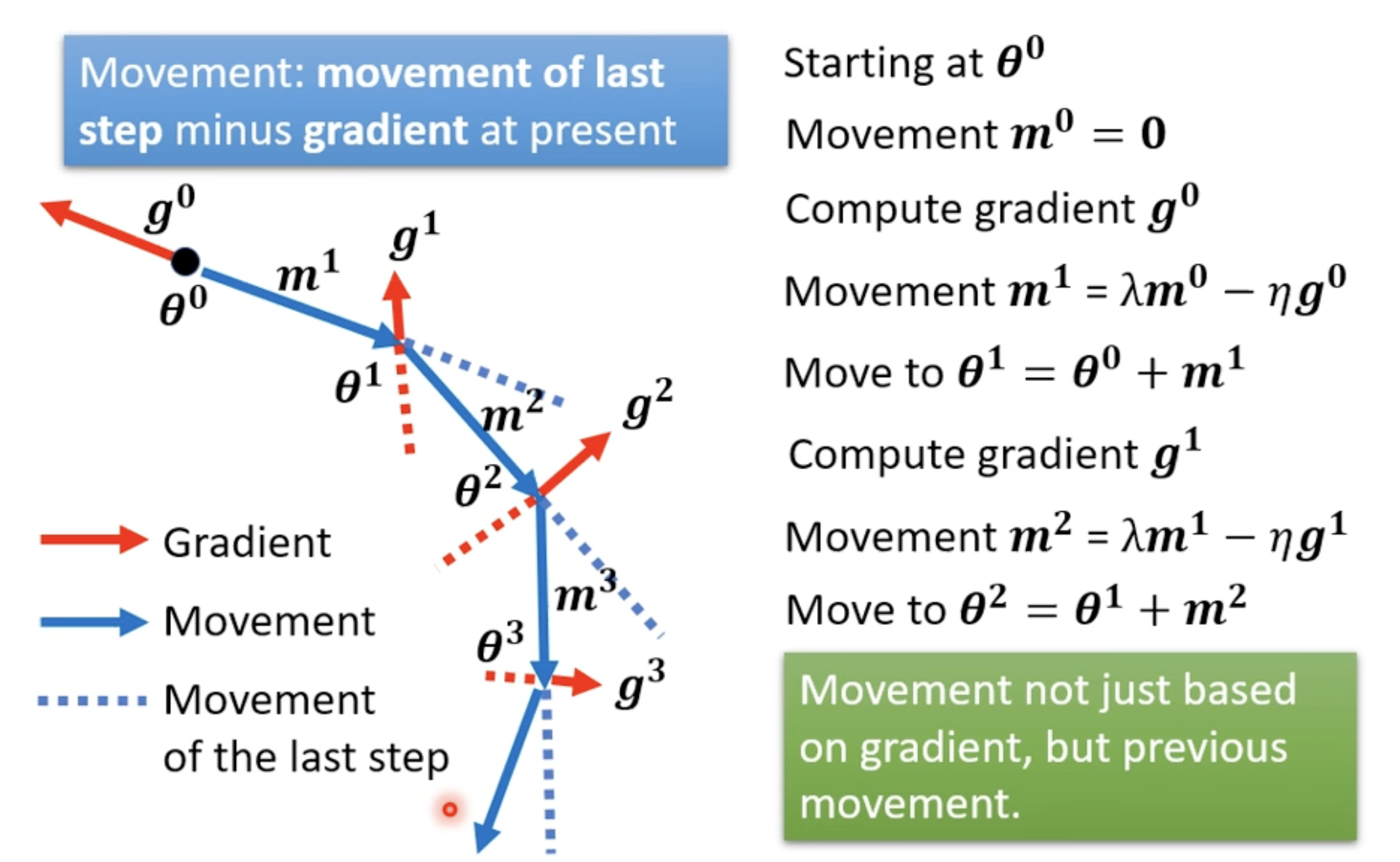
is the weighted sum of all the previous gradient: :
Adaptive Learning Rate 技术
- : Parameter dependant
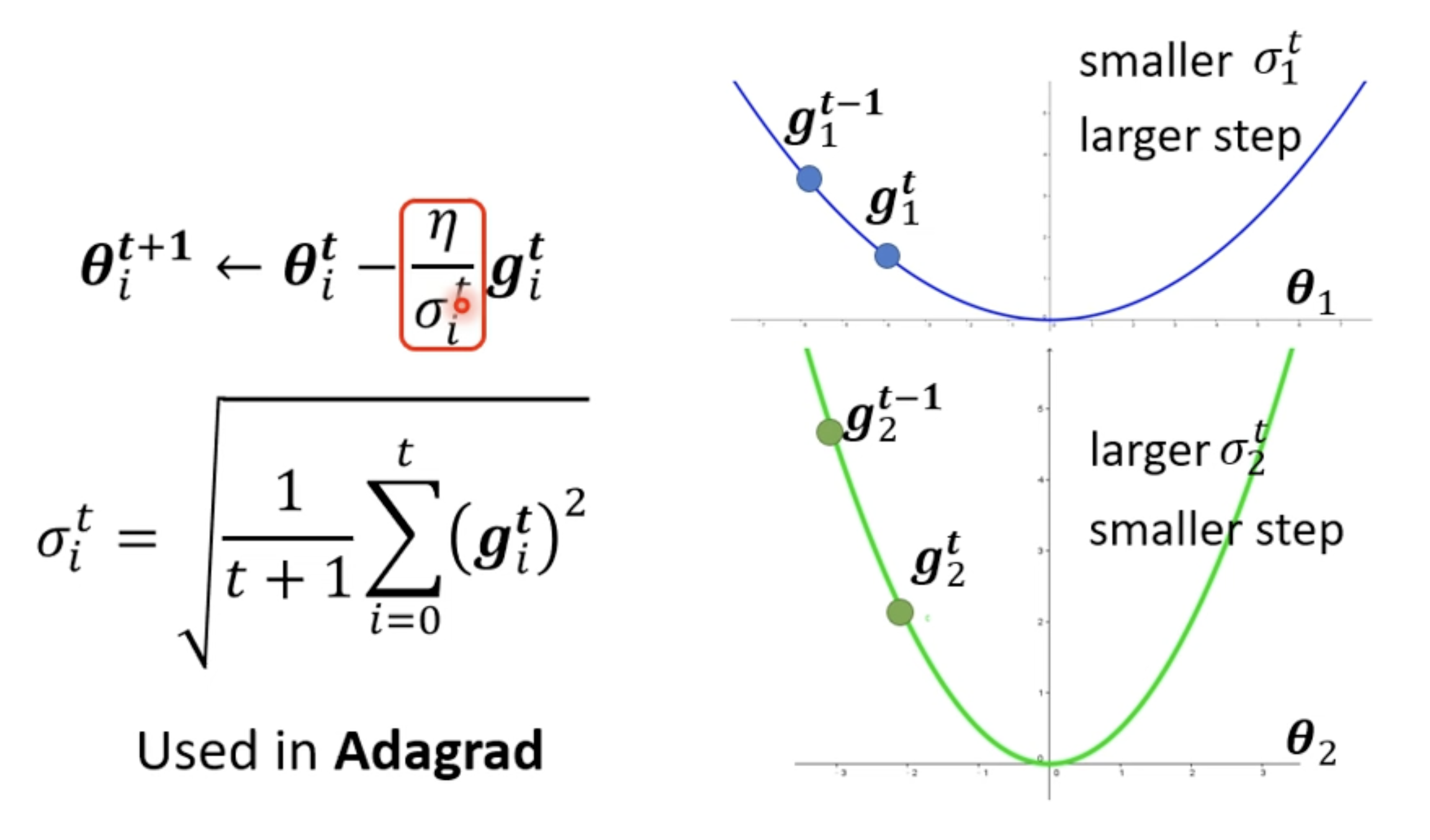
Root Mean Square
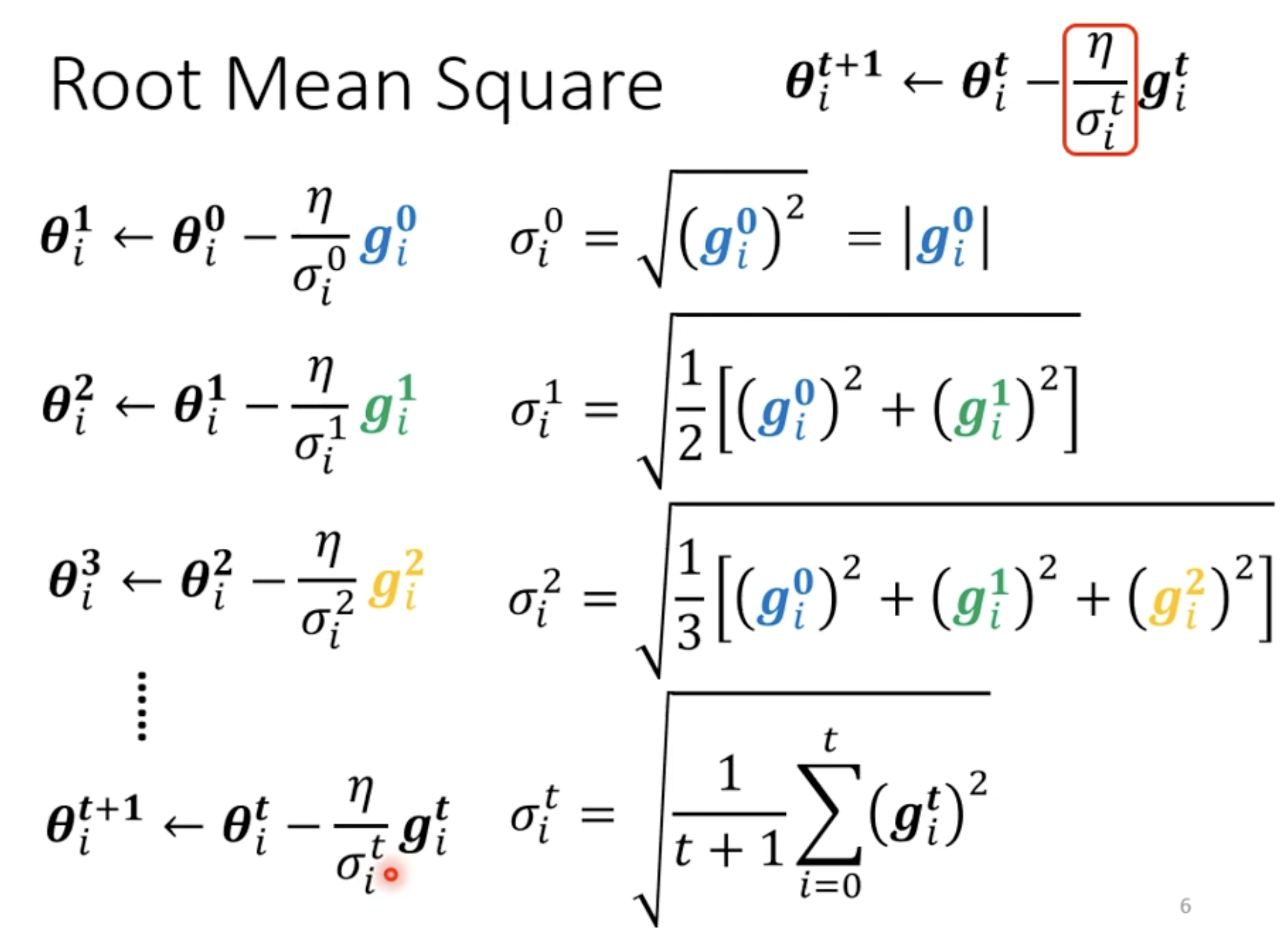
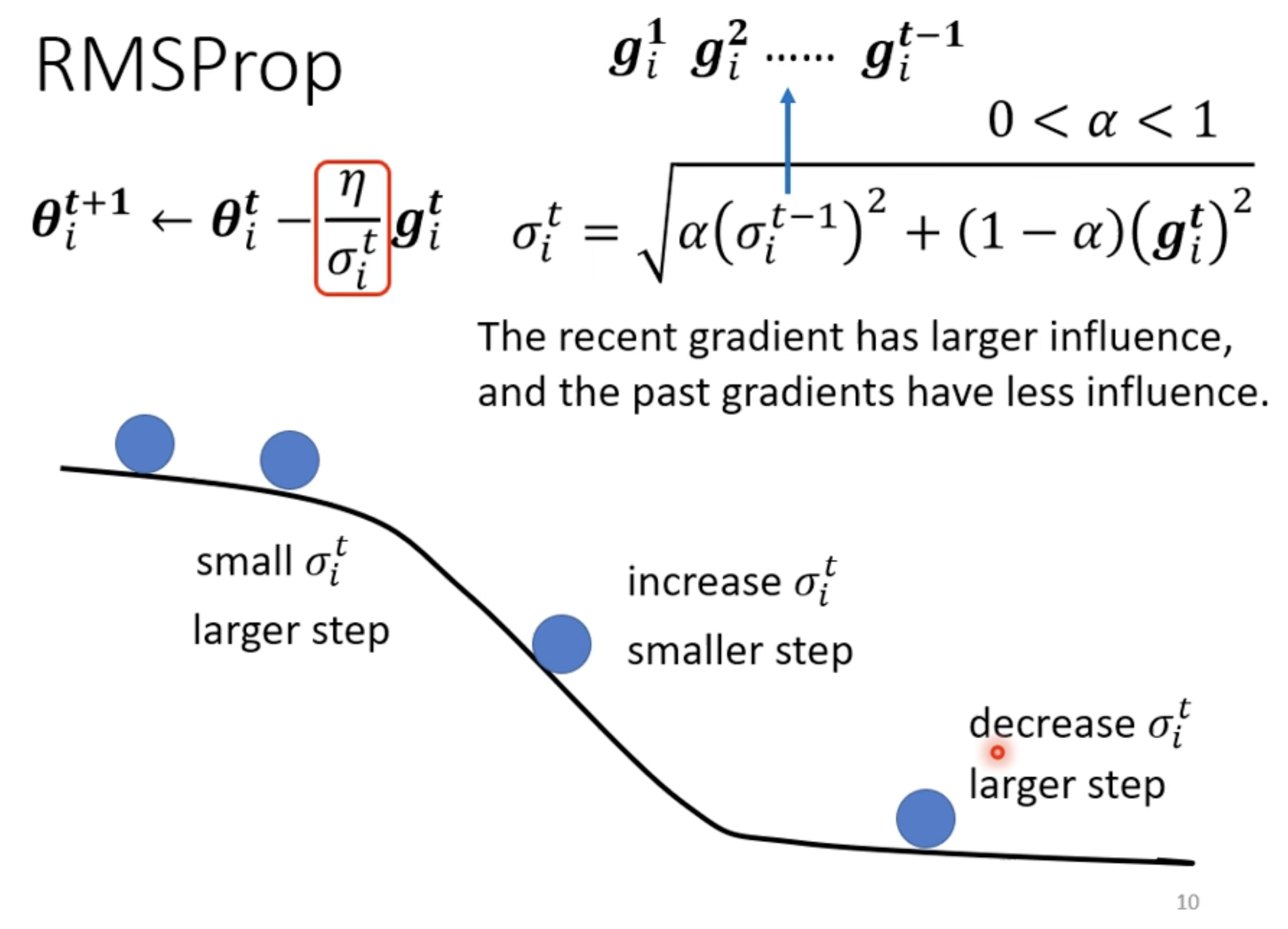
RMSProp
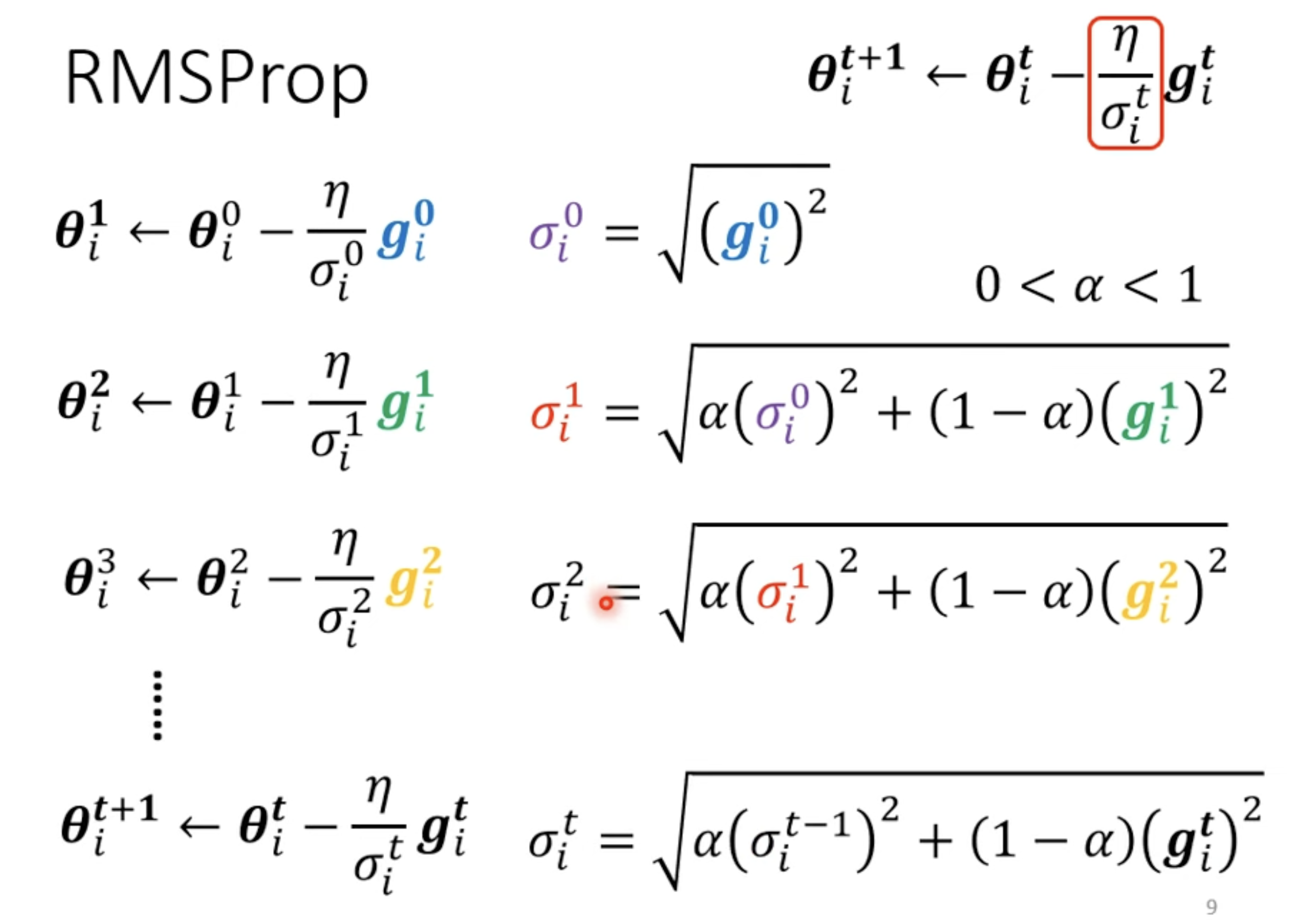
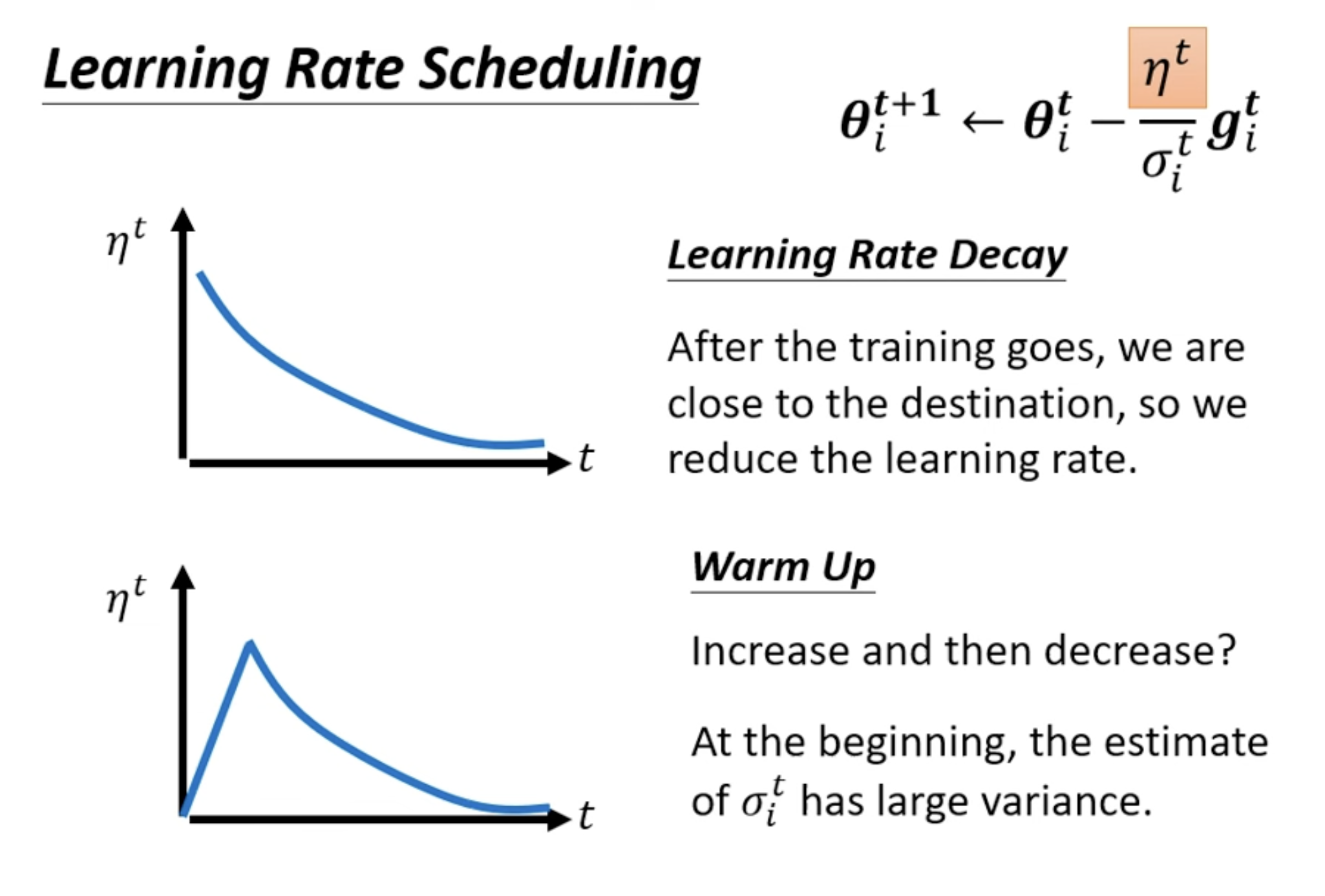
Learning Rate Scheduling
Learning Rate Decay: reduce learning rate by time.