机器学习的训练指南
· 2 min read
基本概念
- Linear model()
- Sigmoid
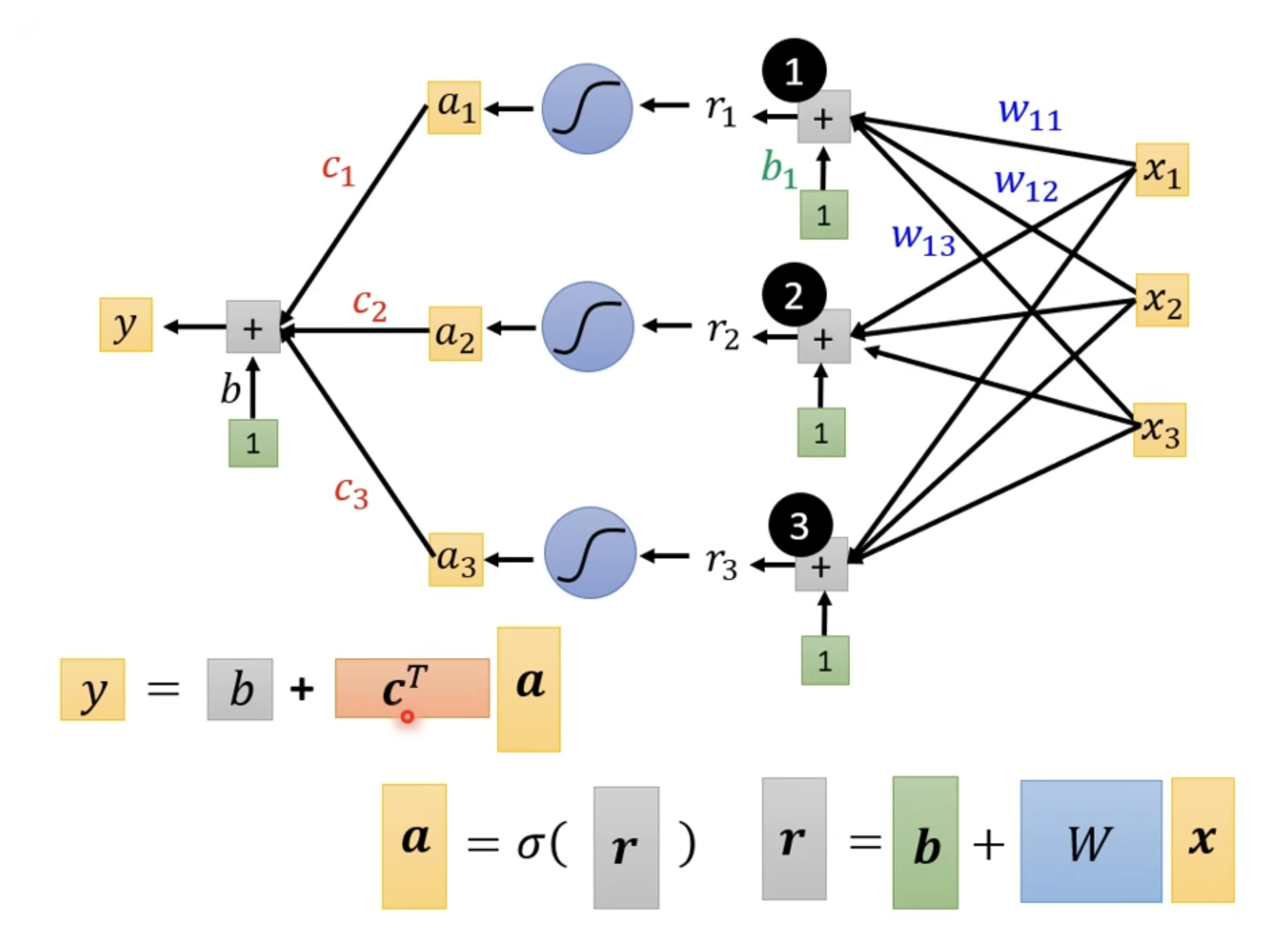
- ReLU
- Multiple layers --> Deep

Gradient descent
Neuro --> Neural Network
Many layers mean Deep --> Deep learning
Deep = Many hidden layers
Question: Deep or "Fat" ?
Issue: Overfitting
数据
-
训练数据(Training data):
-
测试数据(Testing data):
-
Speech Recognition
-
Image Recognition
-
Speaker Recognition
-
Machine Translation
训练步骤

指南
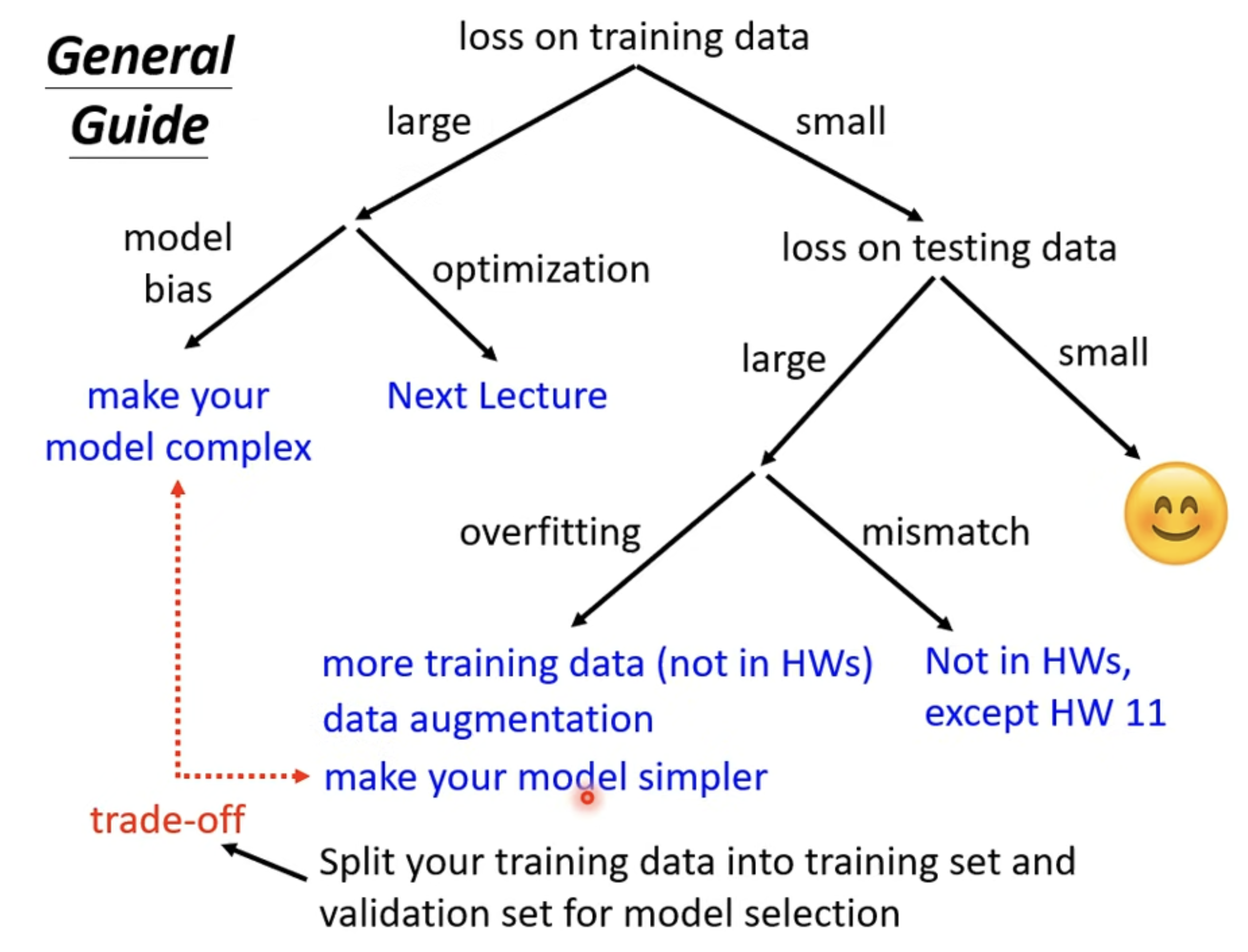
Model bias
- The model is too simple: Redesign your model to make it more flexible.
- 增加输入的信息内容 (More features)
- Deep learning (More neurons, layers)
Optimization
- Large loss not always imply model bias. There is other possibility.
Model Bias vs Optimization Issue
- Gaining the insights from comparison

- Start from shallower networks (or other models), which are easier to optimize.
- If deeper networks do not obtain smaller loss on training data, then there is optimization issue.
Overfitting
-
Small loss on training data, large loss on testing data.
-
Solution
- Data
- More training data
- Data augmentation

- Constrained model (like )
- Less parameters, sharing parameters
- Less features
- Early stopping
- Regularization
- Dropout
- But not contrain too much (like , this is a issue of model bias)
- Data
Mismatch
- Your training and testing data have different distributions.
- Be aware of how data is generated.
对你训练资料和测试资料的产生方式有理解,才能知道是不是 Mismatch 问题。
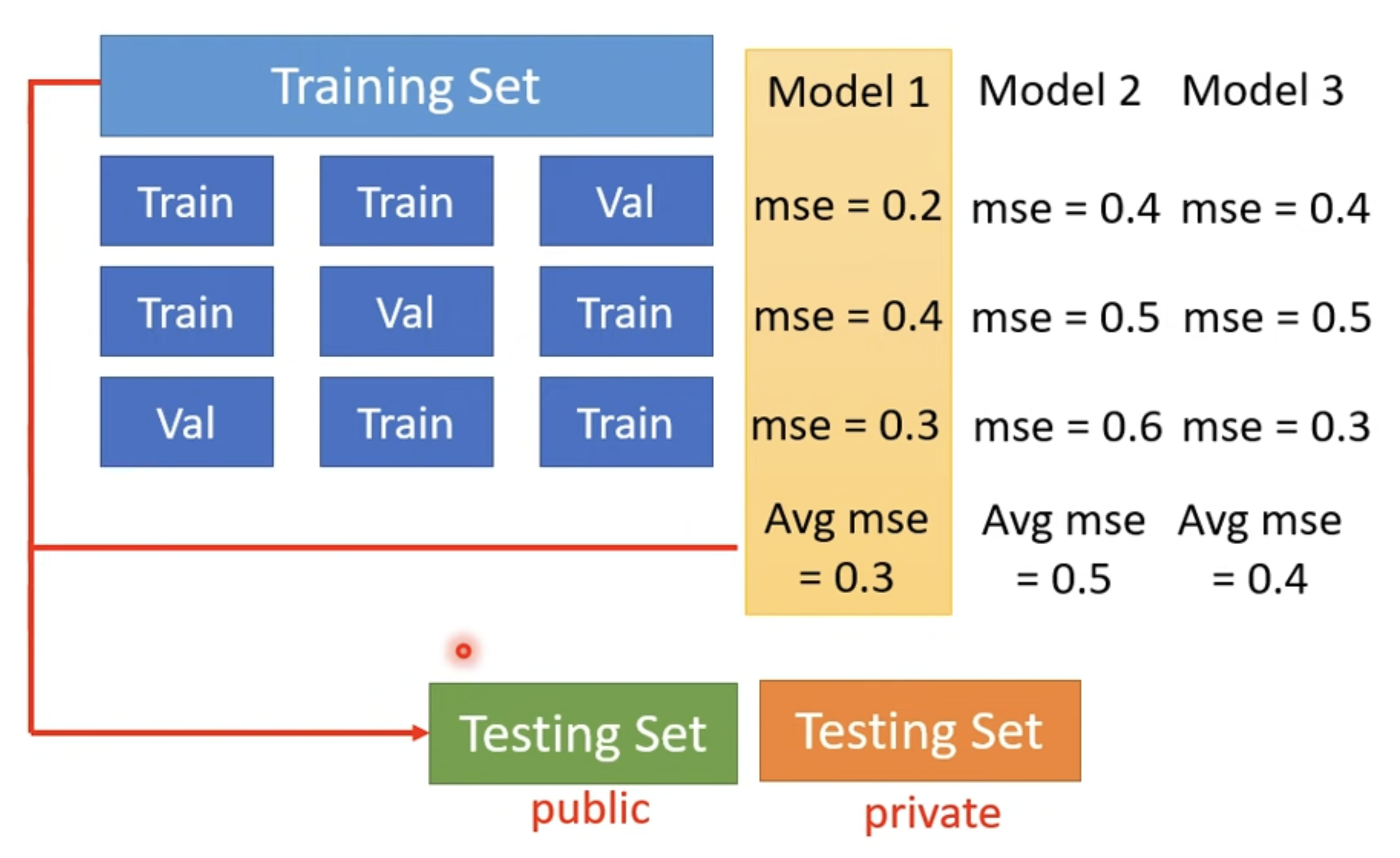
Cross Validation
- Training Set
- Training Set 90%
- Validation Set 10%
- Testing Set
- public
- private
N-Fold Cross Validation