Advanced RAG: Pre-Retrieval (optimising indexing)
Chunking Strategies
把内容拆分成更小的模块。
- 内容类型
- 内容大小
- 用户查询复杂度
- 应用使用目的
分块策略
- Fixed-size (character) overlapping sliding window: 确保句子完整性。
- Recursive structure-aware splitting: 确保章节(内容结构)完整性。
- Structure aware splitting (by sentence, paragraph): 分辨内容结构(句子、段落、节、章节)并拆分。
- Content-aware splitting: 分析内容再决定使用什么工具拆分。
- Chunking through
NLTKTextSplitterfrom Langchain: 按照自然语言 (Natural Language Tookit) 单位切分句子。 - Semantic chunking: 利用机器学习的语意来拆分内容。
- Agentic chunking: 使用大模型代理,捕捉文本的更深层次含义和结构。
颗粒度(数据清洗)
从数据中删除不相关的信息和不一致之处。
- Stop words removal: 删除没有意义的停顿词。
- Specal character removal: 删除特殊字符,比如 html Tag 符号。
- Text normalization: 全部小写(Lowercasing),词干提取/词形还原(Stemming/Lemmatization)
- Fact-checking and updating information: 验证内容,集成事实核查、知识图谱验证,定期更新。
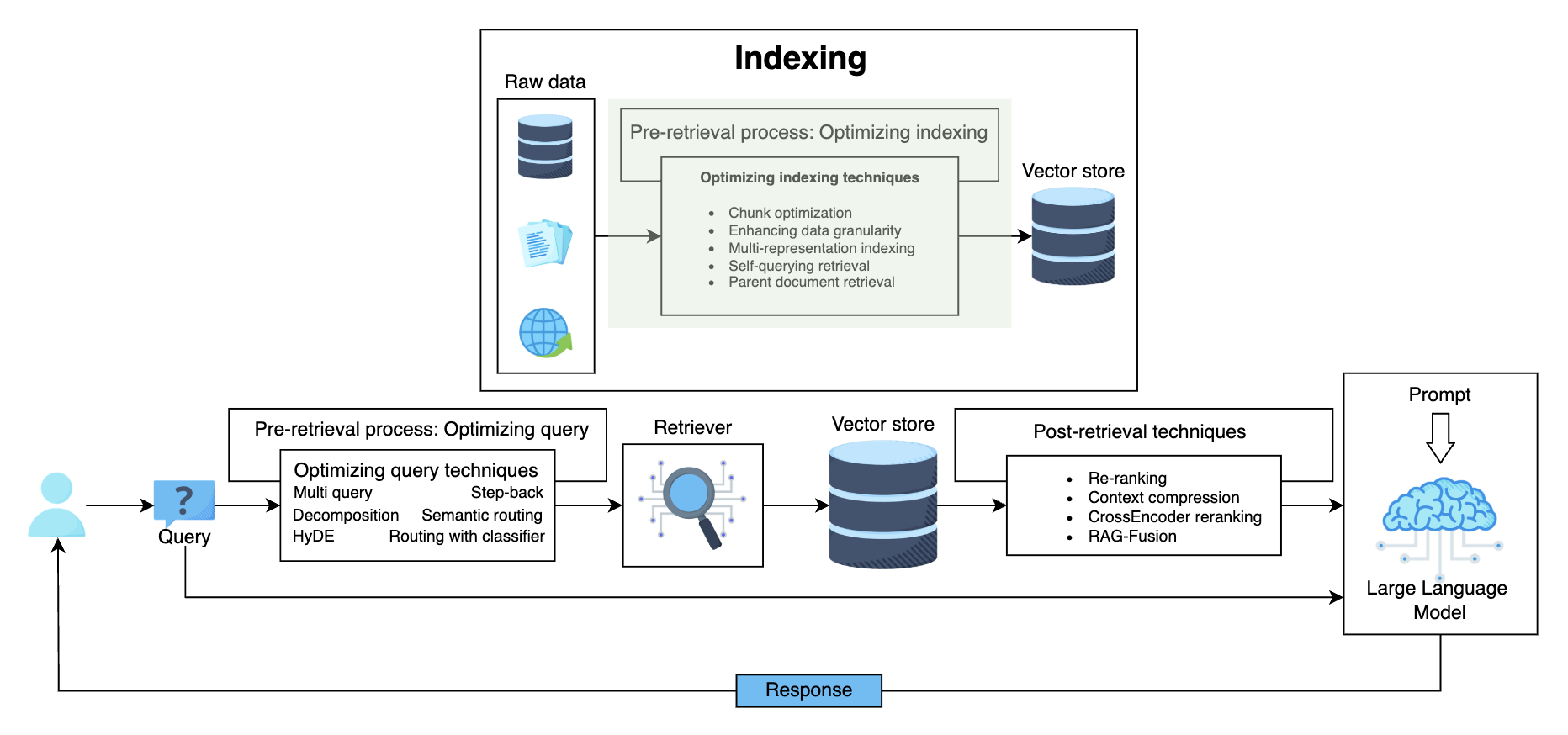
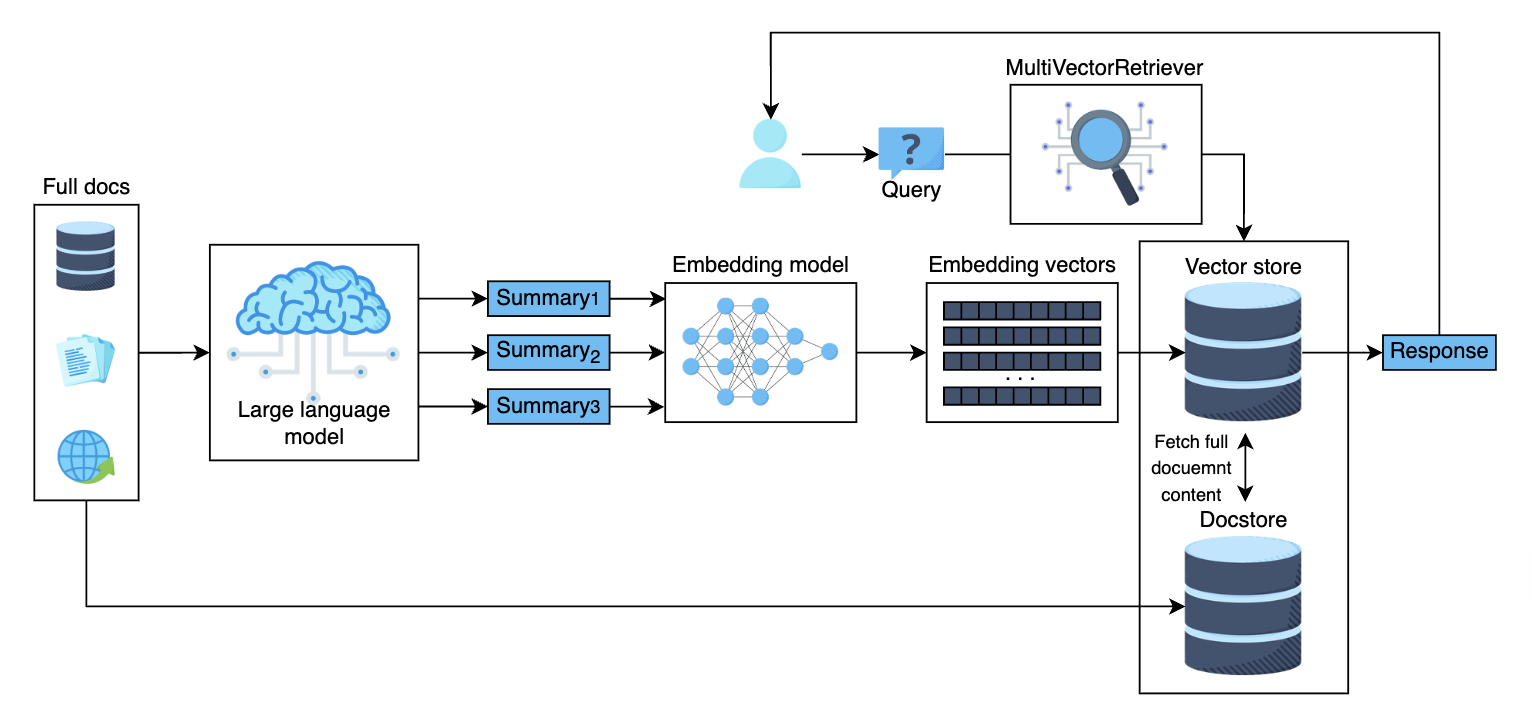
多表示索引 (Multi-Representation Indexing)
多表示索引涉及在检索系统中创建和存储每个文档的多个表示。这些表示可以从不同的技术中得出,例如:
- Textual analysis
- Semantic embeddings
- Visual features
自查询索引 Self-Querying Retrieval (SQR)
利用 LLM 的强大功能来了解用户在文档集合中的意图。
- Document representation
- User query
- LLM-driven retrieval
- Refine and repeat
父文档索引 Parent Document Retrieval (PDR)
父文档检索 (PDR) 是高级 RAG 模型中使用的一种技术,用于检索相关资段落的完整父文档。
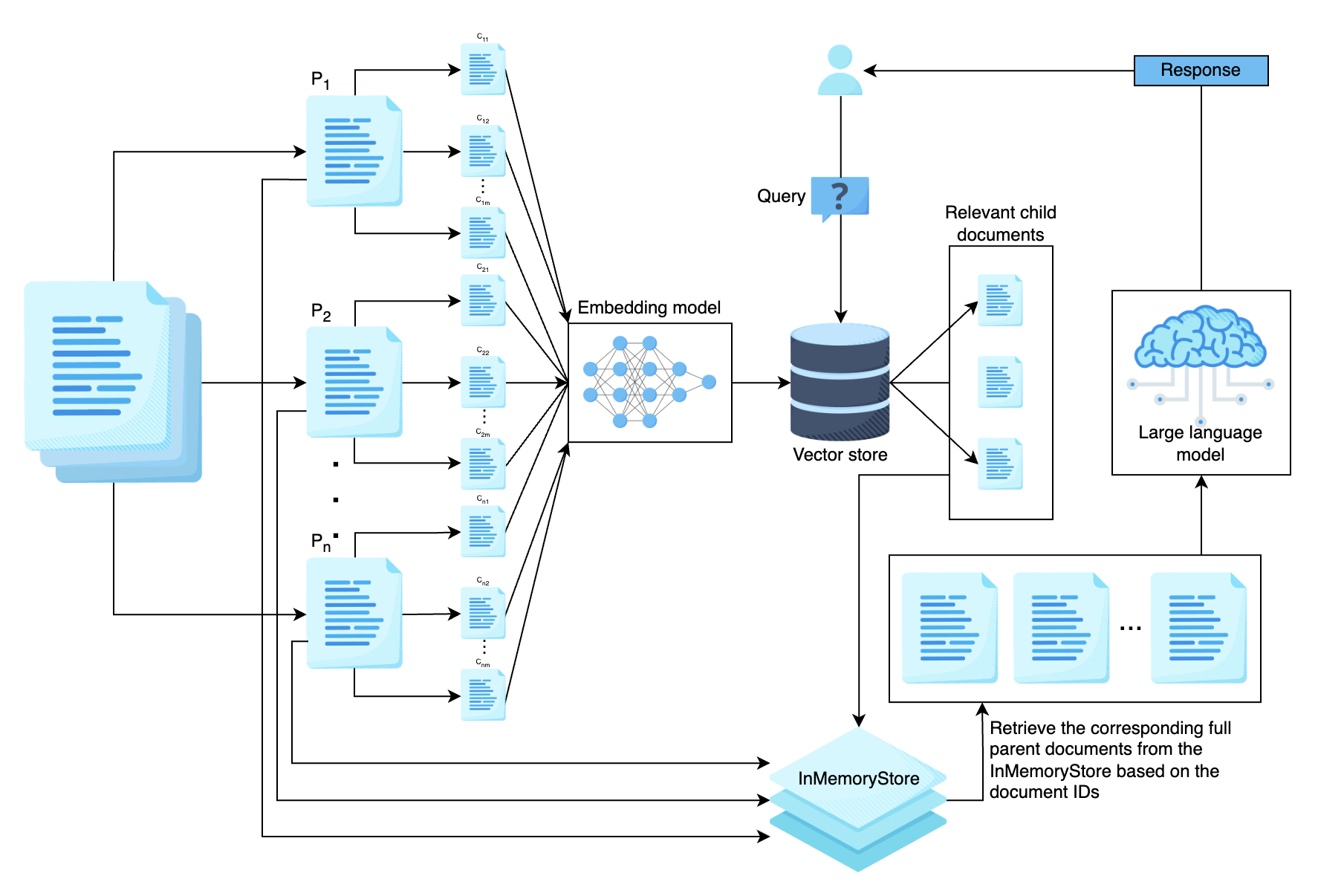
- ParentDocumentRetriever.parent_splitter
- ParentDocumentRetriever.child_splitter