检索-增强 生成 RAG
Benefits of using RAG
Applications of RAG
RAG paradigms
Tree main approaches/paradigms
- Naive RAG: This is the simplest RAG approach. It retrieves relevant document chunks based on a user query and provides them as context for an LLM to generate a response.
- Advanced RAG: Building on naive RAG, advanced versions incorporate optimization strategies for better retrieval accuracy and LLM context integration.
- Modular RAG: The most flexible RAG architecture breaks down the process into modules that can be swapped and customized for specific tasks, offering better control and adaptability.
Naive RAG: The Simplest Retrieval-Generative Integration
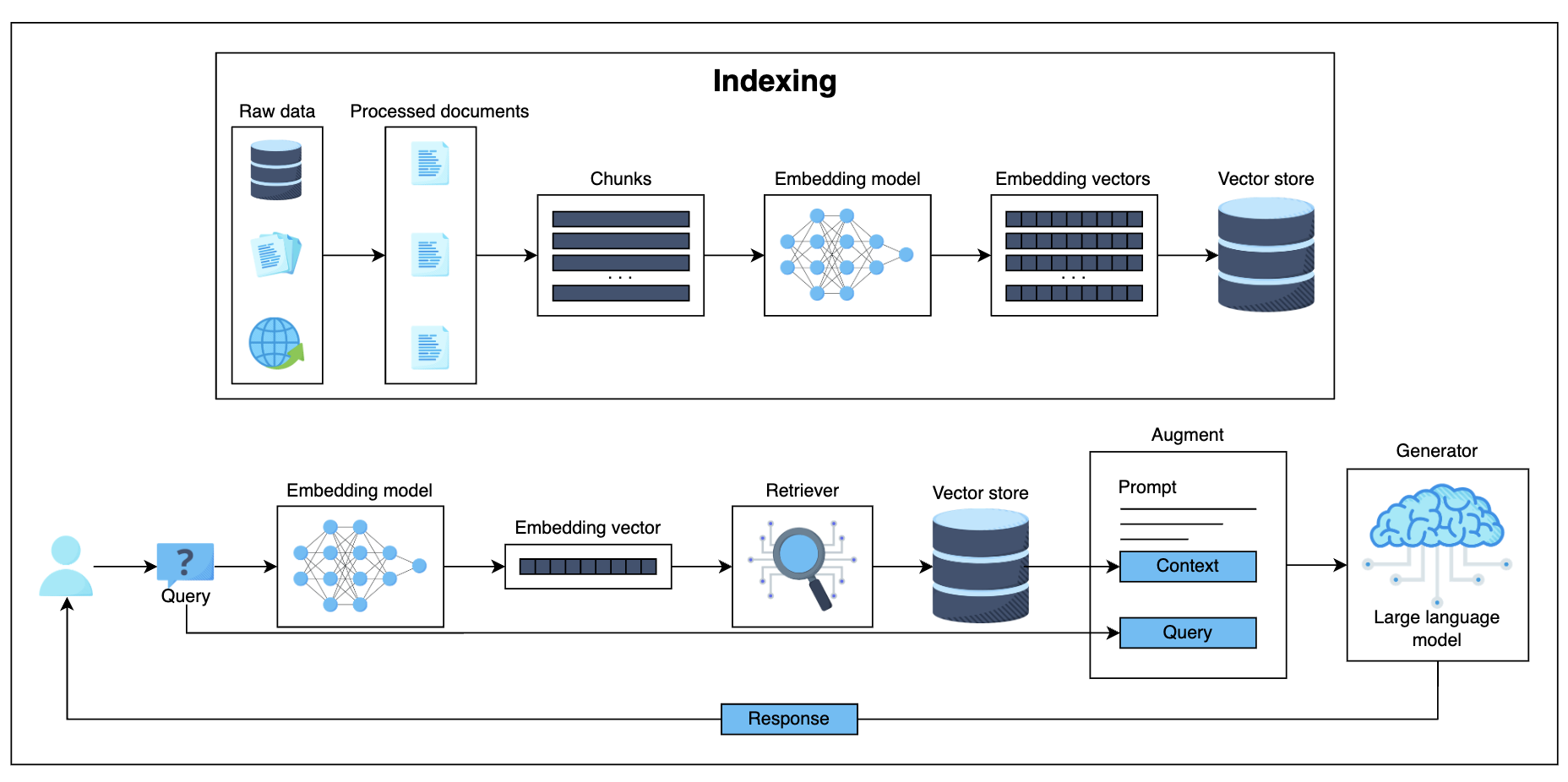
Limitations of naive RAG
| Stage | Challenges |
|---|---|
| Retrieval | Difficulty in finding relevant and accurate information Inclusion of irrelevant chunks Missing crucial details |
| Generation | Potential for response unsupported by retrievved-context(hallucination) Risk of generating irrelevant, toxic, or biased reponse |
| Augmentation | Challenges in effectively integrating retrieved information Disjointed outputs Redundancy Complexity in determining the significance of different passages Ensuring stylistic consistency |
Advanced RAG: Enhancing Model Efficiency and Accuracy
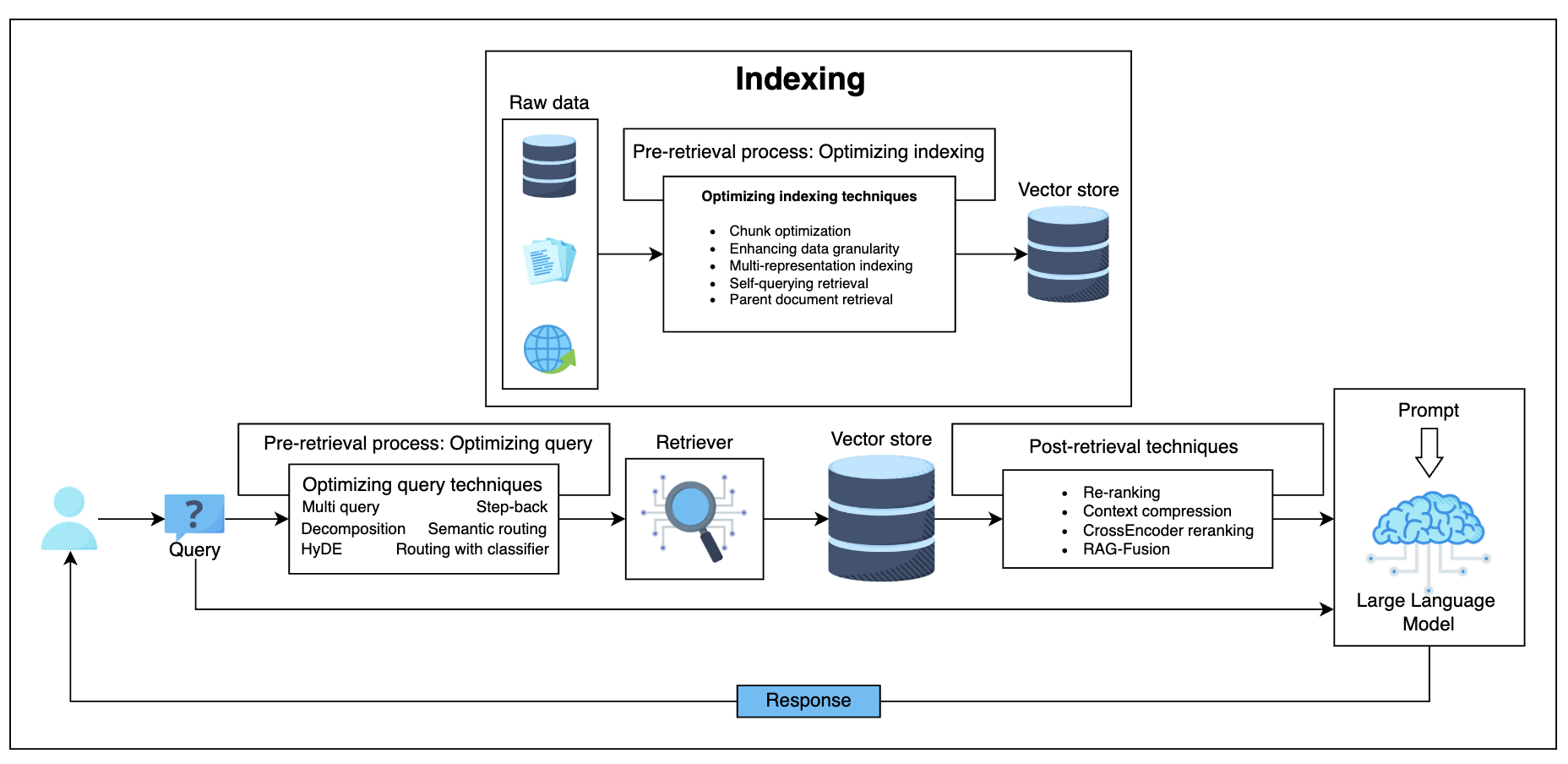
Pre-retrieval process
Optimizing indexing
- Enhancing data granularity (chunking strategies):
- Enhancing data granularity (data cleaning)
- Multi-representation indexing
- Self-querying retrieval
- Optimizing index structures
- Parent document retrieval
Optimizing query
- Multi-query
- Decomposition
- Step back prompting
- Query routing
Retrieval process
- Query vectorization
- Similarity search
Post-retrieval process
- Reranking
- Context compression
- Inference-based filtering
Trade-offs of pre- and post-retrieval processes
| Process | Benefits | Drawbacks |
|---|---|---|
| Pre-retrieval |
|
|
| Post-retrieval |
|
|
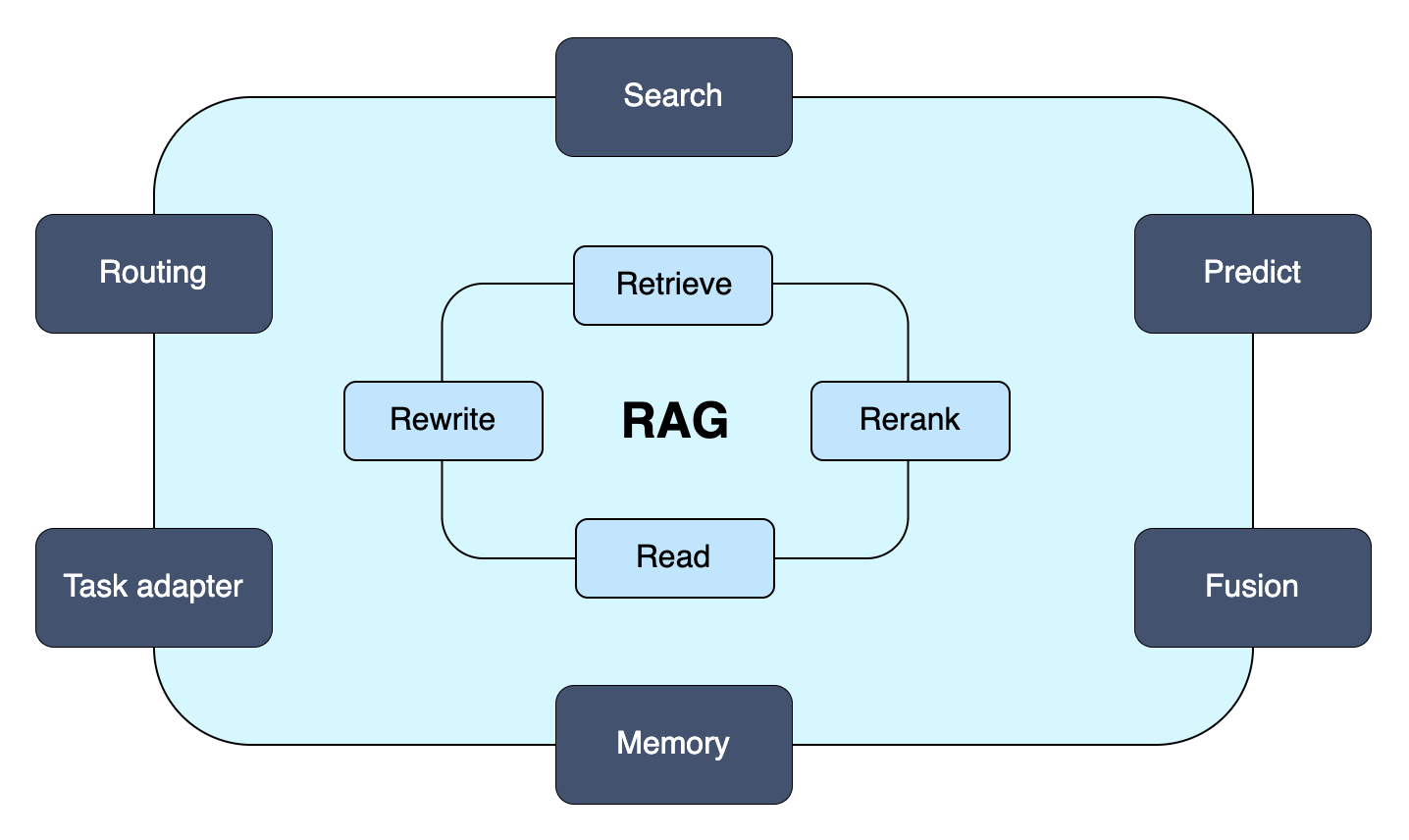
Modular RAG: Building Flexible RAG Pipelines
- Search module
- Rag-Fusion
- Memory module
- Routing module
- Predict module
- Task adapter module
Choosing the Best Approach for Your RAG Application
| Paradigm | Description | Pros | Cons | Applications |
|---|---|---|---|---|
| Naive RAG (Retrieve-Read) | Simplest paradigm with indexing, retrieval, and generation. | Easy to implement, computationally, efficient. | Limited control over retrieved information, LLM might struggle with synthesis. | Simple question answering, short document summarization. |
| Advanced RAG (Retrieve-Read-Rewrite-Rerank) | Builds on Naive RAG with pre-retrieval and post-retrieval processing for improved retrieval quality. | More control over information, improved response relevance. | More complex to implement than Naive RAG. | Complex question answer, longer document summarization. |
| Modular RAG (Flexible Architecutre) | Most versatile paradigm with specialized modules for enhanced retrieval and processing. | Highly customizable, allows for experimentation and innovation. | Most complex to implment, requires deeper understanding of individual RAG components. | Domain-specific question answering, tailored creative text generation tasks. |
- Complexity of the task
- Domain-specific requirements
- Computational resources